HDFS 机架感知详解

互联网公司的 Hadoop 集群一般都会比较大,几百台服务器会分布在不同的机架上,甚至在不同的机房。出于保证数据安全性和数据传输的高效性的平衡考虑,HDFS希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架和跨机房。同时,NameNode 在分配 Block 的存储位置的时候,会尽可能把数据块的副本放到多个机架甚至机房中,防止机架出现事故或者机房出现事故时候的数据丢失问题发生。
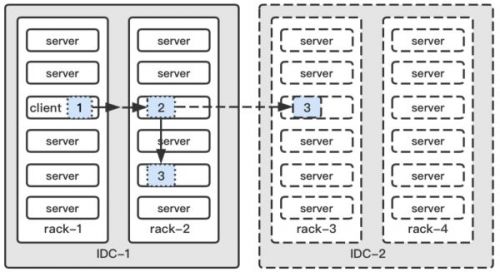
这就是 HDFS 的机架感知,首先机房和机架的信息是需要用户自己配置的,HDFS 没法做到自动感知,然后根据配置的信息,NameNode 会有如下的副本放置策略。
- 第一个 block 副本放在 Client 所在的服务器,如果 client 不在集群服务器中,则这第一个 DataNode 会随机选择。
- 第二个副本放置在与第一个节点不同的机架中的节点中,保证机架间的高可用。
- 第三个有不同机房则跨机房随机放置在某个节点上;只有一个机房则和第二副本在同一个机架,随机放在不同的节点中。
- 更多的副本,则继续随机放置,需要注意的是一个节点最多放置一个副本。
HDFS 读流程中如何找到最佳节点? 这个放置策略其实也就是上一篇中提到的 HDFS 读流程中如何找到最佳节点的答案。读的过程,会首先找离 Client 最近的 DataNode,保证读的高效避免资源浪费,先后顺序依次是:
1. 与 Client 在同一服务器
2. 在同一机架
3. 在同一个机房
4. 跨机房
更多关于“大数据培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!








