Spark groupByKey 和 reduceBykey 区别
发布时间:2022-08-12 10:25:05
发布人:syq

reduceByKey 可以接收一个 func 函数作为参数,这个函数会作用到每个分区的数据上,即分区内部的数据先进行一轮计算,然后才进行 shuffle 将数据写入下游分区,再将这个函数作用到下游的分区上,这样做的目的是减少 shuffle 的数据量,减轻负担。
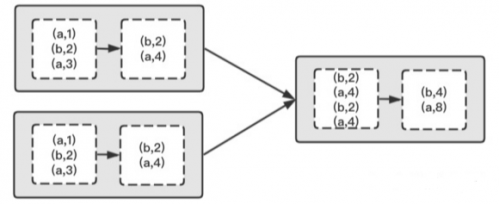
groupByKey 不接收函数,Shuffle 过程所有的数据都会参加,从上游拉去全量数据根据 Key 进行分组写入下游分区,这样会消耗比较多的资源,数据传输会导致任务处理的延迟。
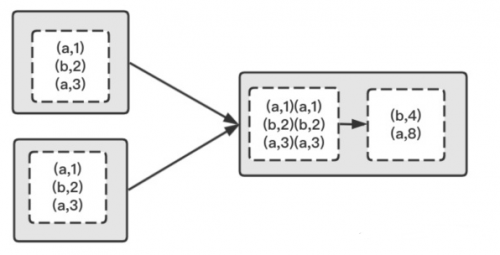
如果我们想要进行分组后进行聚合操作,使用 reduceByKey 会更高效, 因为reduceByKey 会在map阶段合并分区内相同的key,而gourpByKey 则不会合并。
更多关于大数据培训的问题,欢迎咨询千锋教育在线名师。千锋教育拥有多年IT培训服务经验,采用全程面授高品质、高体验培养模式,拥有国内一体化教学管理及学员服务,助力更多学员实现高薪梦想。
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!








