一文带大家轻松掌握requests模块

上周的爬虫文章中我们介绍了urllib模块,我们知道urllib模块可以模拟浏览器发送请求并获取响应信息。同时我们也介绍了urllib模块是Python的内置模块,可以直接通过import导入使用。
requests模块介绍
本篇文章我们继续给大家介绍模拟浏览器发送请求并获取响应信息的requests模块,那为什么我们有了urllib模块还要学习requests模块呢?
• 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
– 手动处理url编码
– 手动处理post请求参数
– 处理cookie和代理操作繁琐
– ......
• 使用requests模块:
– 自动处理url编码
– 自动处理post请求参数
– 简化cookie和代理操作
我们如何使用requests模块呢?
因为requests模块不是Python的内置模块,所以我们要通过包管理器pip进行下载。
安装:
pip install requests
或者
pip3 install requests
安装完成之后我们就可以在py文件中导入使用了
import requests
requests模块使用
我们前面说过爬虫的基本步骤是:
• 获取url以及url分页的规律
• 发送请求【可以使用urllib或者requests】
• 获取响应对象中的数据值
• 持久化存储数据
发送请求的方式有:GET和POST,多数的请求是GET请求,比如在做数据查询时,建议用GET请求方式。而在做数据添加、修改或删除或者用户登陆这些场景的时候就是POST请求,因为GET请求方式的安全性较POST方式要差些,包含机密信息的话,建议用POST数据提交方式。
requests模块官方文档链接:https://docs.python-requests.org/zh_CN/latest/user/quickstart.html,如果有任何疑问大家也可以尝试查看文档,练习尝试阅读文档对于大家学习其他模块会有很大好处。
本文分别从两种请求方式介绍requests模块的使用
requests模块发送get请求
requests的作用就是发送网络请求,返回响应数据,那么现在有一个简单的需求:通过requests向百度首页发送请求,获取百度首页的数据。
import requests
# url即百度首页的链接
url = 'https://www.baidu.com'
# 通过get方法向目标url发送get请求,返回响应的结果,是一个response对象
response = requests.get(url)
# 打印响应内容
print(response)
打印结果大家看到:
<Response [200]>
但是我们如何像urllib一样查看响应对象的状态码、响应体内容呢?因为返回的是Response对象,所以对象就可以访问下面的属性和方法。如下:
response.text 读取服务器响应的内容,通常使用response.text会自动解码来自服务器的内容。因此大多数 unicode 字符集都能被无缝地解码
response.encoding 获取文本编码,也可以使用该属性修改编码
response.content 获取响应内容的二进制形式,一般图片、音视频等使用此方式获取
response.status_code 获取当前请求的响应码
response.headers 获取响应的响应头
response.cookies 获取响应的cookies内容
response.url 获取请求的url
接下来我们以爬取百度,检索的关键词是【Python】为例,看一下响应内容。
import requests
url='https://www.baidu.com/'
response = requests.get(url=url)
# 获取响应的状态码
print(response.status_code)
# 获取编码方式
print(response.encoding)
html_data = response.text
print(html_data)
# content获取的是response对象中的二进制(byte)类型的页面数据
print(response.content)
# 返回一个响应状态码
print(response.status_code)
# 返回响应头信息
print(response.headers)
# 获取请求的url
print(response.url)
结果:

而如果使用requests保存图片,则需要结合文件保存完成。
import requests
# 图片地址
image_url = 'https://anchorpost.msstatic.com/cdnimage/anchorpost/1082/bc/e60d649dd5fa645b575f73f9aef0bc_2168_1617694516.jpg?imageview/4/0/w/338/h/19'
# 发送请求获取响应
response = requests.get(url)
with open('girl.png', 'wb')as f:
f.write(response.content)
获取图片就不能像获取文本内容一样使用response.text,而要使用response.content. 获取的内容最后通过open()函数进行本地保存。
上面的请求都没有添加请求头,比如我们要爬取豆瓣的内容就会得到418的响应状态码,因为发送的请求没有请求头。
为什么请求需要带上header?
因为网站往往都会检测请求头的User-Agent,如果ua不合法,可能会获取不到响应。所以加请求头的目的就是模拟浏览器,欺骗服务器,获取和浏览器一致的内容。当然,有的时候甚至不止需要传User-Agent一个参数,请求信息还需要其他的参数像Referer,Cookie等等
requests添加请求头如何实现呢?
通过字典的形式。多个请求头信息,使用多个键值对的形式。
headers = {"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10143) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
用法
requests.get(url, headers=headers)
后面的headers就是字典
我们以豆瓣的信息检索为例,比如我们在豆瓣上查询【阿凡达】
import requests
import pprint
# 检索阿凡达的信息
url = 'https://www.douban.com/search?q=%E9%98%BF%E5%87%A1%E8%BE%BE'
# 定义headers请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"
}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
# 使用pprint进行格式化的输出
pprint.pprint(response.text)
结果:
大家发现在上面的豆瓣请求中是有参数的,就是【?】后面的内容部分。上面案例中将阿凡达直接进行了编码。那如果有参数requests主要如何使用呢?
url 带参数的两种请求方式
方式一:直接跟在请求链接的后面,如https://www.baidu.com/s?wd=python。 wd=python就是参数。多个参数之间使用符号【&】链接.
https://www.baidu.com/s?wd=Python&pn=10
https://www.baidu.com/s?wd=Python&pn=20
https://www.baidu.com/s?wd=Python&pn=30
在wd=Python和pn=10之间使用符号【&】
# 方式一:直接发送带参数的url的请求
import requests
headers = {"User-Agent": "ozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=Python'
# url中包含了请求参数,即在请求链接处?位置后面就是携带的参数
response = requests.get(url, headers=headers)
print(response.text)
方式二:使用params实现,类似headers的使用。先定义一个字典params ={'wd':'Python','pn':10}
使用:
requests.get(url, headers=headers,params=params)
后面的params就是携带的参数
import requests
headers = {"User-Agent": "ozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
# 下面的url如果使用params可以省略?
url = 'https://www.baidu.com/s'
# 请求参数是一个字典 即wd=Python和pn=10
params = {'wd':'Python','pn':10}
# 在params上设置字典
response = requests.get(url, headers=headers, params=params)
# 获取结果并打印
print(response.text)
但是还有检索的内容是中文的情况怎么处理?因为我们大多数使用百度搜索内容都是中文的内容。requests模块好用之处就在此,如果检索的内容是中文,直接写成中文就可以了,我们无需自己转码的。方便吧?
requests模块发送post请求
那么哪些地方我们会用到POST请求?
登录注册( POST 比 GET 更安全)
需要传输大文本内容的时候( POST 请求对数据长度没有要求)
用法:
response = requests.post("请求地址", data = 字典类型的参数,headers=字典类型的请求头)
本次案例我们使用http://httpbin.org/测试网址,在这个网站中你可以测试使用不同的请求方法。
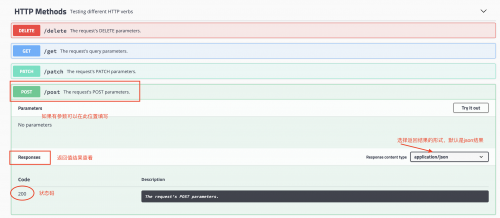
代码:使用response对象下面的json()获取。
import requests # 导入网络请求模块requests
# 字典类型的表单参数
data = {
'a': '好好学习,天天向上!',
'b': '强身健体,天天Happy'
}
#发送网络请求
response = requests.post('http://httpbin.org/post', data=data)
print(response.json()) #打印转换后的响应数据
返回的是一个json字符串结果。如果想将结果转成字典形式就要使用json模块的loads()完成
import requests # 导入网络请求模块requests
import json # 导入json模块
# 字典类型的表单参数
data = {
'a': '好好学习,天天向上!',
'b': '强身健体,天天Happy'
}
#发送网络请求
response = requests.post('http://httpbin.org/post', data=data)
response_dict = json.loads(response.json())#将响应数据json转换为字典类型
print(response_dict) #打印转换后的响应数据
代理ip的使用
为什么要使用代理?
为了让服务器认为不是同一个客户端在请求,因为同一个客户端的ip地址是固定不变的,使用ip代理就可以不断的切换ip地址,这样就可以防止我们的真实地址被泄露,甚至被追究。
正向代理和反向代理
正向代理:给客户端做代理,隐藏客户端的ip地址,让服务器不知道客户端的真实ip地址
反向代理: 给服务器做代理,隐藏服务器的真实ip地址,同时可以实现负载均衡,处理静态文件请求等作用,比如nginx
在使用过程中,从请求使用的协议可以分为3种,但是使用哪一种,要在使用的时候需要根据抓取网站的协议来选择。
http代理
https代理
socket代理等

找了一些代理网站,但是有些网站是要付费的,根据需求决定是否需要付费使用。
http://ip.kxdaili.com/ 开心代理
https://proxy.mimvp.com/free.php 米扑代理
http://www.xiladaili.com/ 西拉免费代理IP
http://ip.jiangxianli.com/ 免费代理IP库
http://www.superfastip.com/ 极速代理
https://proxy.mimvp.com/free.php 米扑代理
http://www.shenjidaili.com/open/ 神鸡代理IP
http://31f.cn/http-proxy/ 三一代理
http://www.feiyiproxy.com/?page_id=1457 飞蚁代理
http://ip.zdaye.com/dayProxy/2019/4/1.html 站大爷
http://www.66ip.cn 66免费代理网
https://www.kuaidaili.com/free/inha 快代理
https://www.xicidaili.com 西刺
http://www.ip3366.net/free/?stype=1 云代理
http://www.iphai.com/free/ng IP海
http://www.goubanjia.com/ 全网代理
http://www.89ip.cn/index.html 89免费代理
http://www.qydaili.com/free/?action=china&page=3 旗云代理
import requests
import random
# 代理的使用
url = "https://www.baidu.com"
# 获取的代理ip地址,放在一个字典中,可以写多个使用随机数不断变化选取
# 注意:免费代理的地址是有失效时间的,自己可以去上面网站找合适的
ips = ['221.222.84.131:9000','124.42.7.103:80','116.214.32.51:8080','222.73.68.144:8090','117.121.100.9:3128']
proxy = {
'http': random.choice(ips),
}
response = requests.get(url, proxies=proxy)
print(response.text)
如果爬取的内容是多页,就可以每页随机的选择ip地址使用了。
代理IP使用的注意点:
反反爬使用代理ip是非常必要的一种反反爬的方式,但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:一段时间内,检测IP访问的频率,访问太多频繁会屏蔽;检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽;服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽等。所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。
好喽!对于这些内容大家还满意吗?如果还有不清楚的欢迎大家留言哦!下次我们学习正则表达式在爬虫的使用哦!更多关于Python培训的问题,欢迎咨询千锋教育在线名师,如果想要了解我们的师资、课程、项目实操的话可以点击咨询课程顾问,获取试听资格来试听我们的课程,在线零距离接触千锋教育大咖名师,让你轻松从入门到精通。







