你们数据量级多大?分库分表怎么做的?
发布时间:2022-09-15 15:58:14
发布人:wjy

首先分库分表分为垂直和水平两个方式,一般来说我们拆分的顺序是先垂直后水平。
垂直分库
基于现在微服务拆分来说,都是已经做到了垂直分库了
垂直分表
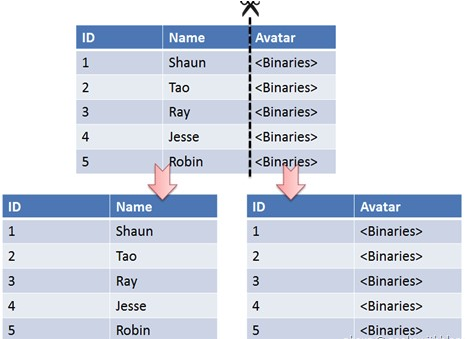
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
水平分表
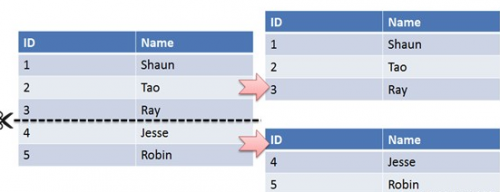
首先根据业务场景来决定使用什么字段作为分表字段(sharding_key),比如我们现在日订单1000万,我们大部分的场景来源于C端,我们可以用user_id作为sharding_key,数据查询支持到最近3个月的订单,超过3个月的做归档处理,那么3个月的数据量就是9亿,可以分1024张表,那么每张表的数据大概就在100万左右。
比如用户id为100,那我们都经过hash(100),然后对1024取模,就可以落到对应的表上了。
那分表后的ID怎么保证唯一性的呢?
因为我们主键默认都是自增的,那么分表之后的主键在不同表就肯定会有冲突了。有几个办法考虑:
设定步长,比如1-1024张表我们分别设定1-1024的基础步长,这样主键落到不同的表就不会冲突了。
分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种
分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。






