谈谈对scrapy的了解?

一:对scrapy的认识:
1.scrapy只是一个爬虫的框架
他把爬虫的需要的共性的东西都默认写下来了,只需要我们具体细化,具体分析补充里面的细节的东西。就像造房子一样,scrapy就充当了一个房屋架构,至于房屋里面的东西 需要我们自己去补充设计。
2.scrapy的几个部分
引擎(engine) 爬虫(spider)调度器(scheduler) 下载器(downloader) items文件pipeline(管道文件) settings.py(进行对爬虫修改的东西,比如UserAgent可以注释掉,pipline管道文件可以将其关闭,从而不使用管道文件,robots协议可以改为False)
3.各个部分的作用
引擎的作用:处理scrapy这几个部分之间的联系,像人类的大脑,由引擎控制其他各个部分,扮演一个事情通知员的角色,是其他部分之间联系的桥梁。
调度器:使我们需要爬取的Url做一个个有序排列
下载器:从云端internet上下载东西
spider:爬虫 对爬虫的编写,实现爬取数据,是整个爬虫的主干
items文件:需要爬取的字段写在里面 如:name=scrapy.Field()
pipeline:管道文件,用来写存储代码的,将爬取的数据存储到本地或者数据库
ps:以上大概了解下各个部分的职能就好了。
二.scrpay框架实现爬虫的模拟的简要过程:
1.首先引擎告诉spider我们需要爬取的数据的网域domain,然后spider给引擎作出回应表示知道了
2.引擎告诉调度器(scheduler)‘需要你排序啦’,然后spider将域告诉调度器,调度器将域里面每个需要爬取的url做一个排序,然后对引擎说‘’ 我排好序了’’
3.引擎就对下载器说‘调度器排好序了,你待会需要从云端下载东西了’ 。。。下载器就准备开始以一个个的url里面下载我们写的item文件,下载好后,对引擎说‘’我下载好了“
4.引擎就开始对spider说“下载器把items文件下好了”,下载器将下载的item文件(响应文件)给spider,spider将得到的items文件(响应文件)给pipline管道进行存储,同时将继续要爬取的URl给调度器,然后调度器,然后周而复始 直到需要爬取的url爬完。
写spider(爬虫)中需要注意的
1. name是必要参数,是scrapy爬虫的名字。domain域可选参数,可以没有,start_urls必要的参数,是指开始要爬取的url。
2. def parse(self,response) 这个函数是就这个名字,scrapy中定了的,是对响应文件做出处理的函数。
3. yield 生成器函数,生成一个新的函数,再对数据做出进一步处理 如:
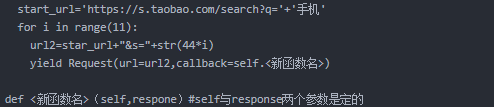
ps:yield自己理解的也不是很清楚,见谅。
4. xpath中的.extract()方法:从一个列表中(脱壳)得到一个新的列表。一心得到标签里面的元素,以列表形式返回
(1)第一种
position = response.xpath(’./td[1]/a/text()’)[] 技术类 2 深圳 2018ps:没有extract()的时候,整个标签的东西都拿下来了。返回的是一个selector对象(2)第二种
position = response.xpath(’./td[1]/a/text()’).extract()[‘22989-腾讯云虚拟化高级研发工程师(深圳) 技术类 2 深圳 2018’]
(3)第三种
position=response.xpath‘./td[1]/a/text()’).extract[0]22989-腾讯云虚拟化高级研发工程师(深圳) 技术类 2 深圳 2018
scrapy写爬虫的步骤:
1. 新建项目:scrapy startproject <项目名>,创建爬虫 scrpay genspider <爬虫名> “爬取数据的域 如:www.cqggzy.com”
2. 明确自己需要爬取的数据,写items字段
3. 编写spider爬虫
4. 存储:编写管道文件
注意事项:
scrapy默认setting.py中管道文件是关闭的,需要打开,请求头在settings中最好将headers也打开,UserAgent最好修改全面一点。robots协议也可以改为False。






