常见的反扒手段

反扒的手段,基本是基于以下三种:
• 基于身份识别进行反爬
• 基于爬虫行为进行反爬
• 基于数据加密进行反爬
身份识别的反爬:
通过headers字段来反爬
headers知识补充:
host:提供了主机名及端口号
Referer 提供给服务器客户端从那个页面链接过来的信息(有些网站会据此来反爬)
Origin:Origin字段里只包含是谁发起的请求,并没有其他信息.(仅存于post请求)
User agent: 发送请求的应用程序名(一些网站会根据UA访问的频率间隔时间进行反爬)
proxies: 代理,一些网站会根据ip访问的频率次数等选择封ip.
cookie: 特定的标记信息,一般可以直接复制,对于一些变化的可以选择构造.
通过请求参数来反爬
常见的有:
通过headers中的User-Agent字段来反爬、通过referer字段或者是其他字段来反爬。如果Python写的爬虫不加入User-Agent,在后台服务器是可以看到服务器的类型pySpider。
通过cookie限制抓取信息,比如我们模拟登陆之后,想拿到登陆之后某页面信息,千万不要以为模拟登陆之后就所有页面都可以抓了,有时候还需要请求一些中间页面拿到特定cookie,然后才可以抓到我们需要的页面。
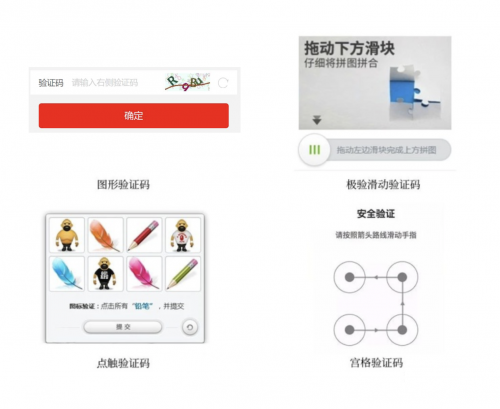
最为经典的反爬虫策略当属“验证码”了。最普通的是文字验证码,因为是图片用户登录时只需输入一次便可录成功,而我们程序抓取数据过程中,需要不断的登录,手动输入验证码是不现实的,所以验证码的出现难倒了一大批人。当然还有滑块的,点触的的(比如12306的点触验证等)。
另一种比较常见的反爬虫模式当属采用JS渲染页面了。就是返回的页面并不是直接请求得到,而是有一部分由JS操作DOM得到,所以那部分数据我们也拿不到咯。
基于爬虫行为进行反爬
基于请求频率或总请求数量的反扒,这是一种比较恶心又比较常见的反爬虫策略当属封ip和封账号,当你抓取频率过快时,ip或者账号被检测出异常会被封禁。被封的结果就是浏览器都无法登陆了,但是换成ip代理就没有问题。