分析时间序列数据的六个图表

本文在 Python 中用箱线图、傅里叶变换、熵、自相关和 PCA 分析时间序列数据。数据可视化是任何数据相关项目中最重要的阶段之一。根据数据可视化的对象有:

1.数据可视化报告结果。
2.数据可视化来分析数据,换句话说,数据科学家内部使用的可视化来提取有关数据的信息,然后实施模型。
本文主要关注后一种,因为它解释了一些有助于分析时间序列数据的方法。
什么是时间序列?
基本数值时间序列是有序的、带时间戳的观测值(测量值)的集合,其中每个观测值都是从同一测量过程中获得的数值标量。
什么是时间戳?
在我们将“时间”捕获为数据点之前,我们不会深入探讨需要精确定义的许多细节(准确性、格式、日历约定、时区等等)。我们将时间戳定义为具有所需精度的时间点的表示就足够了。例如,这可能是根据某个日历的日期约定(例如“08-06-2020”),或者自 1970 年以来以整数表示的毫秒数(这实际上是 UNIX 纪元约定!)
Python类库
首先,这些是与 notebook 一起使用的库。大多数代码都围绕 NumPy 和 Pandas库,因为数据主要以 Pandas Dataframe 表现的 NumPy 数组。
导入文件
下载数据后,运行以下代码将其导入。
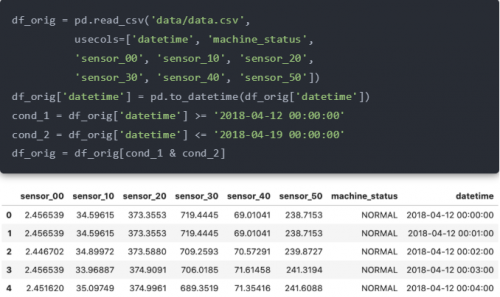
正如所观察到的,数据包含六个传感器的传感器数据、每个数据点的日期时间以及机器状态。这是“BROKEN”、“NORMAL”或“RECOVERING”,但为了简化可视化,它被分组如下:

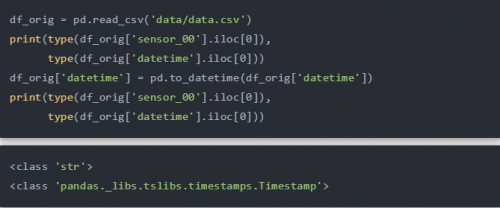
在任何编程语言中使用日期时间总是具有挑战性的,Python 也不例外。尽管处理日期时间有多种方法,但这里使用函数 pandas.to_datetime 将 datetime 列(读取为字符串)转换为时间戳。
数据预处理
在进行可视化之前,分析了本次数据的重复值和缺失值。并且删除重复项的函数:
def drop_duplicates(df: pd.DataFrame(), subset: list = ['DATE_TIME']) -> pd.DataFrame():
df = df.drop_duplicates((subset))
return df
填充缺失值的函数:
def fill_missing_date(df: pd.DataFrame(), column_datetime: str ='DATE_TIME'):
print(f'输入形状: {df.shape}')
data_s = df.drop([column_datetime], axis=1)
datetime_s = df[column_datetime].astype(str)
start_date = min(df[column_datetime])
end_date = max(df[column_datetime])
date_s = pd.date_range(start_date, end_date, freq="min").strftime('%Y-%m-%d %H:%M:%S')
data_processed_s = []
for date_val in date_s:
pos = np.where(date_val == datetime_s)[0]
assert len(pos) in [0, 1]
if len(pos) == 0:
data = [date_val] + [0] * data_s.shape[1]
elif len(pos) == 1:
data = [date_val] + data_s.iloc[pos].values.tolist()[0]
data_processed_s.append(data)
df_processed = pd.DataFrame(data_processed_s, columns=[column_datetime] + data_s.columns.values.tolist())
df_processed[column_datetime] = pd.to_datetime(df_processed[column_datetime])
print(f'输出形状: {df_processed.shape}')
return df_processed
这是预处理阶段的整个管道。此外,数据分为输入数据和输出数据。

输入形状:(10081, 7)
输出形状:(10081, 2)
数据可视化
现在,准备开始数据可视化。这是传感器数据和异常情况的图。完整代码可以在公众号:机器学习研习院 后台回复 时间序列可视化获取.
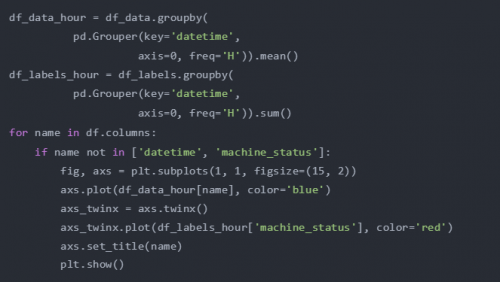
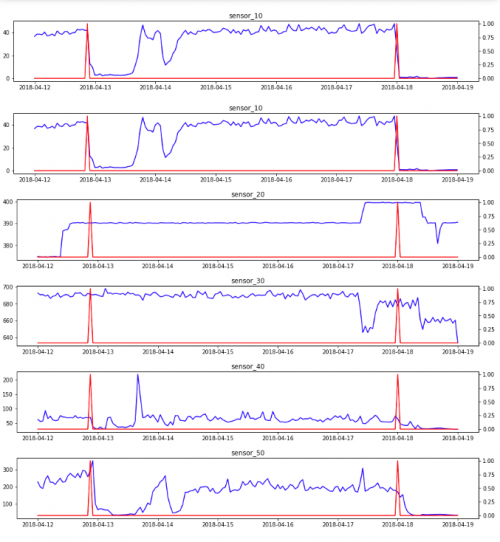
均值和标准
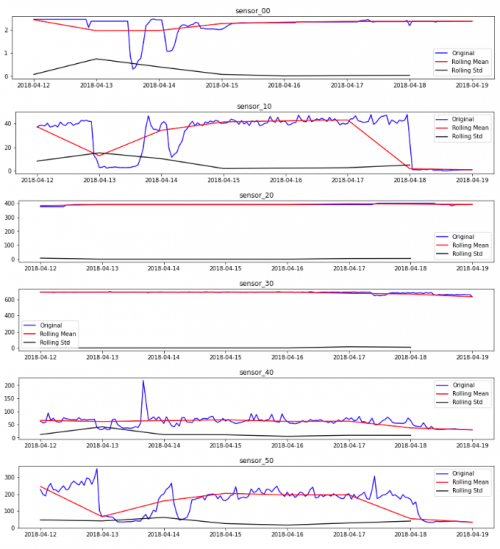
可以更好地总结数据随时间变化的行为的最基本图之一是均值标准图,我们在其中显示按时间范围分组的均值和标准差。这主要有助于分析指定时间范围内的基线和噪声。
df_data_hour = df_data.groupby(pd.Grouper(key='datetime', axis=0, freq='H')).mean()
df_labels_hour = df_labels.groupby(pd.Grouper(key='datetime', axis=0, freq='H')).sum()
df_rollmean = df_data_hour.resample(rule='D').mean()
df_rollstd = df_data_hour.resample(rule='D').std()
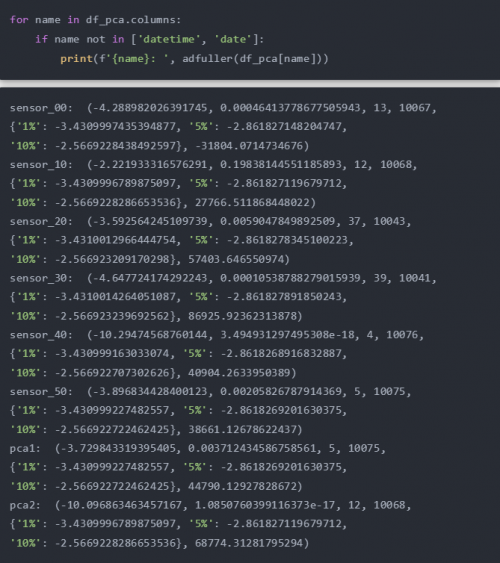
for name in df.columns:
if name not in ['datetime', 'machine_status']:
fig, axs = plt.subplots(1, 1, figsize=(15, 2))
axs.plot(df_data_hour[name], color='blue', label='Original')
axs.plot(df_rollmean[name], color='red', label='Rolling Mean')
plt.plot(df_rollstd[name], color='black', label='Rolling Std' )
axs.set_title(name)
plt.legend()
plt.show()
箱形图
另一个有趣的图表是通过箱线图显示的。箱线图是一种通过四分位数以图形方式显示数值数据的局部性、扩散性和偏度组的方法。有两个主要框表示从第25个百分位数到第75个百分位数的数据,两者之间用分布的中位数隔开。除了盒子之外,还有从盒子延伸出来的晶须,表明上四分位和下四分位之外的变异性。与数据集其他部分显著不同的异常值也被绘制为箱线图上须之外的单独点。
这一个类似于平均和标准图,因为它表明数据的平稳性。但是,它也可以显示异常值,这有助于从视觉上检测异常和数据之间的任何关系。
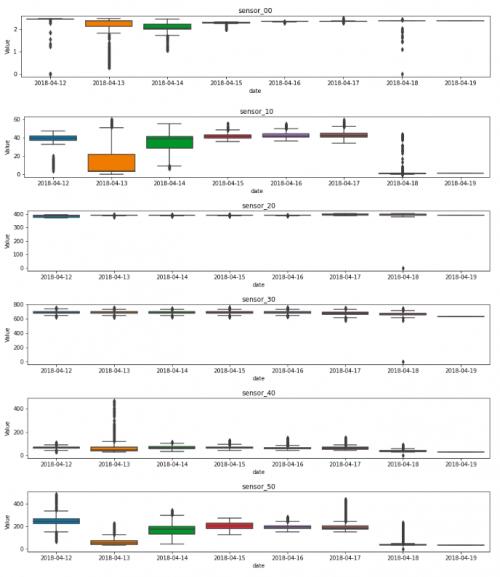
傅里叶变换
快速傅里叶变换(FFT)是一种计算序列离散傅里叶变换的算法。这种类型的图很有趣,因为它是处理时间序列时特征提取的主要方法之一。通常的做法不是用时间序列来训练模型,而是应用傅里叶变换来提取频率,然后训练模型。
为此,我们必须选择一个滑动窗口来计算FFT。滑动窗口越宽,频率数越高。缺点是您将得到更少的时间戳,从而丢失数据的时间分辨率。当减小窗口的大小时,我们得到了相反的结果:更少的频率但更高的时间分辨率。然后,窗口的大小应该取决于任务。
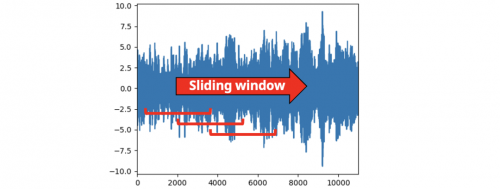
FFT的滑动窗口 对于如下图所示,我选择了一个包含64个数据的时间窗口。因此,频率从1 - 32hz。
def fft(data, nwindow=64, freq = 32):
ffts = []
for i in range(0, len(data)-nwindow, nwindow//2):
sliced = data[i:i+nwindow]
fft = np.abs(np.fft.rfft(sliced*np.hamming(nwindow))[:freq])
ffts.append(fft.tolist())
ffts = np.array(ffts)
return ffts
def data_plot(date_time, data, labels, ax):
ax.plot(date_time, data)
ax.set_xlim(date2num(np.min(date_time)), date2num(np.max(date_time)))
axs_twinx = ax.twinx()
axs_twinx.plot(date_time, labels, color='red')
ax.set_ylabel('Label')
def fft_plot(ffts, ax):
ax.imshow(np.flipud(np.rot90(ffts)), aspect='auto', cmap=matplotlib.cm.bwr,
norm=LogNorm(vmin=np.min(ffts), vmax=np.max(ffts)))
ax.set_xlabel('Timestamp')
ax.set_ylabel('Freq')
df_fourier = df_data.copy()
for name in df_boxplot.columns:
if name not in ['datetime', 'date']:
fig, axs = plt.subplots(2, 1, figsize=(15, 6))
data = df_fourier[name].to_numpy()
ffts = fft(data, nwindow=64, freq = 32)
data_plot(df_fourier['datetime'], data, df_labels['machine_status'], axs[0])
fft_plot(ffts, axs[1])
axs[0].set_title(name)
plt.show()
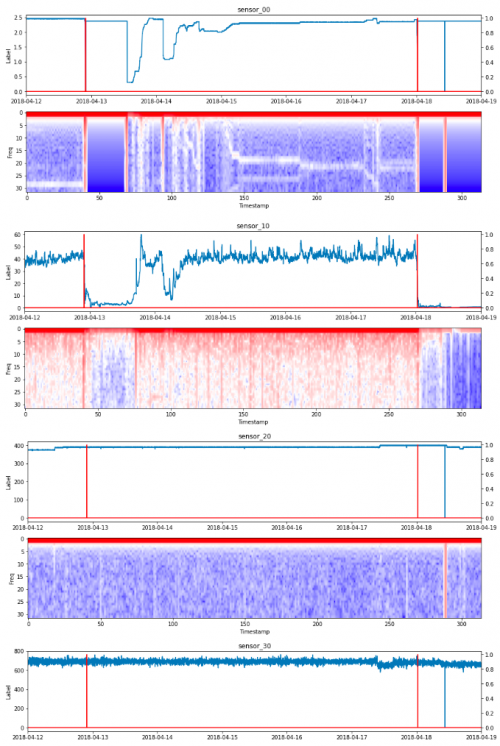
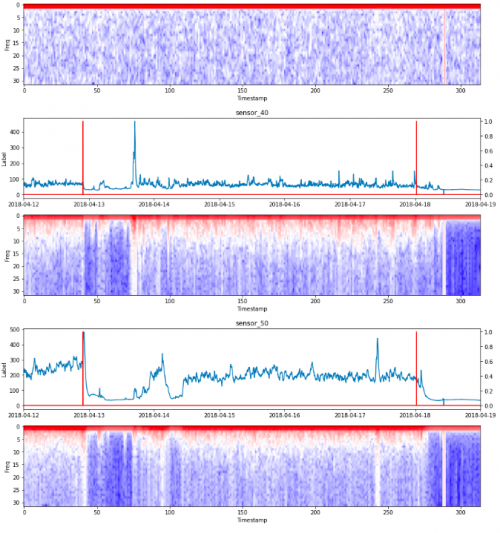
熵
可视化信息和熵是机器学习中的一个有用工具,因为它们是许多特征选择、构建决策树和拟合分类模型的基础。
熵的计算如下:
归一化频率分布
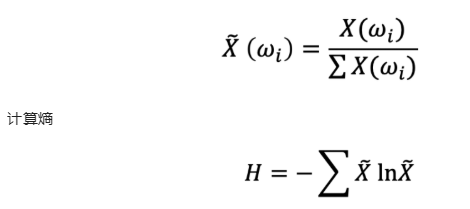
最低熵是针对某一随机变量计算的,该随机变量的单个事件的概率为1.0,即确定性。一个随机变量的最大熵是当所有事件都是等可能的。
def entropy(data, nwindow=64, freq = 32):
entropy_s = []
for i in range(0, len(data)-nwindow, nwindow//2):
sliced = data[i:i+nwindow]
fft = np.abs(np.fft.rfft(sliced*np.hamming(nwindow))[:nwindow//2])
p = fft / np.sum(fft)
entropy = - np.sum(p * np.log(p))
entropy_s.append(entropy)
entropy_s = np.array(entropy_s)
return entropy_s
def data_plot(date_time, data, labels, ax):
ax.plot(date_time, data)
axs_twinx = ax.twinx()
axs_twinx.plot(date_time, labels, color='red')
ax.set_xlabel('Value')
ax.set_ylabel('Label')
def entropy_plot(data, ax):
ax.plot(data, c='k')
ax.set_xlabel('Timestamp')
ax.set_ylabel('Entropy')
df_entropy = df_data.copy()
for name in df_boxplot.columns:
if name not in ['datetime', 'date']:
fig, axs = plt.subplots(2, 1, figsize=(15, 6))
data = df_entropy[name].to_numpy()
entropy_s = entropy(data, nwindow=64, freq = 32)
data_plot(df_entropy['datetime'], data, df_labels['machine_status'], axs[0])
entropy_plot(entropy_s, axs[1])
axs[0].set_title(name)
plt.show()
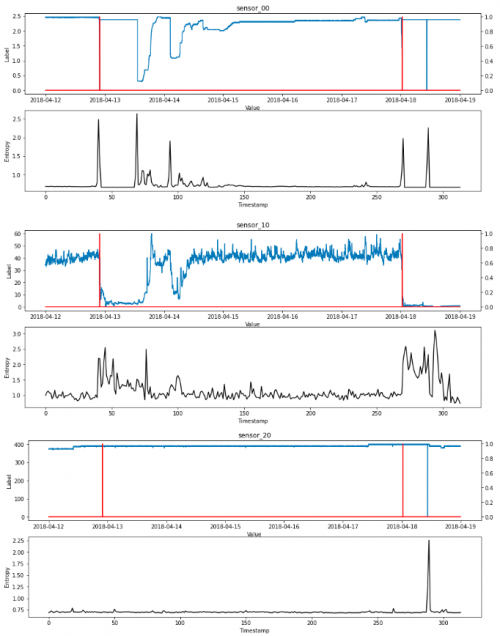
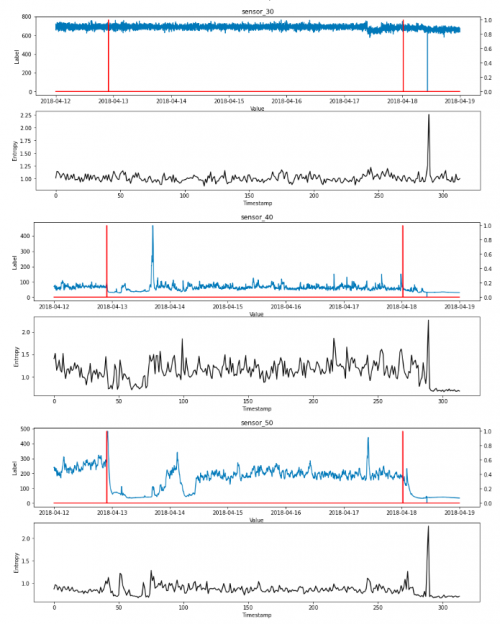
降维
当有多个传感器时,实现一种降维方法来获得包含大部分信息的1、2或3个主要组件总是很有趣的。
对于这个例子,我实现了主成分分析(PCA)。这是计算主要组件并使用它们对数据进行基础更改的过程。
被解释方差比率是每一个被选择的组成部分的方差百分比。
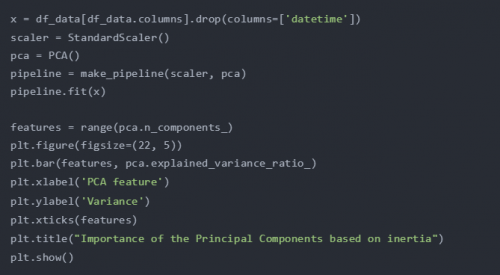

对于第一个PCA组件,可以绘制数据,并直观地检查异常和时间序列之间是否存在关系。
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(x)
principalDf = pd.DataFrame(data = principalComponents, columns = ['pc1', 'pc2'])
df_pca = df_data.copy()
df_pca['pca1'] = pd.Series(principalDf['pc1'].values, index=df.index)
df_pca['pca2'] = pd.Series(principalDf['pc2'].values, index=df.index)
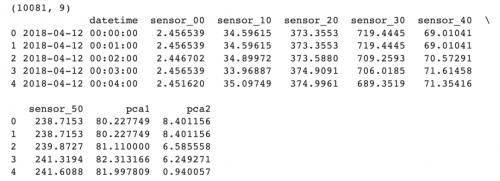
print(df_pca.shape)
print(df_pca.head())
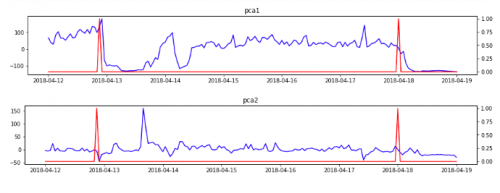
df_pca_hour = df_pca.groupby(pd.Grouper(key='datetime', axis=0, freq='H')).mean()
df_labels_hour = df_labels.groupby(pd.Grouper(key='datetime', axis=0, freq='H')).sum()
for name in df_pca.columns:
if name in ['pca1', 'pca2']:
fig, axs = plt.subplots(1, 1, figsize=(15, 2))
axs.plot(df_pca_hour[name], color='blue')
axs_twinx = axs.twinx()
axs_twinx.plot(df_labels_hour['machine_status'], color='red')
axs.set_title(name)
plt.show()
自相关
最后,特别是对于预测任务,绘制数据的自相关性是很有趣的。这个表示给定的时间序列和它自己在连续时间间隔中的滞后版本之间的相似程度。
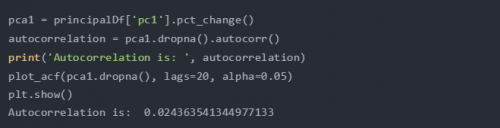
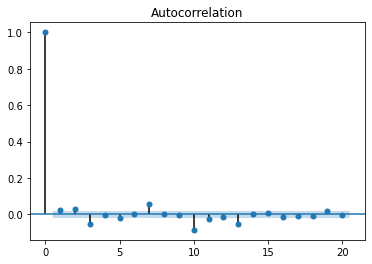
与自相关相关的是增强迪基-富勒统计检验,用于检验给定的时间序列是否平稳。