20天学会爬虫之Scrapy框架通用爬虫CrawlSpider

上篇文章给大家分享的是Spider类的使用,本次我们继续分享学习Spider类的子类CrawlSpider类。
介绍CrawlSpider
CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能。
比如如果你想爬取知乎或者是简书全站的话,CrawlSpider这个强大的武器就可以爬上用场了,说CrawlSpider是为全站爬取而生也不为过。
其中最显著的功能就是”LinkExtractors链接提取器“。Spider是所有爬虫的基类,其设计原则只是为了爬取start_url列表中网页,而从爬取到的网页中提取出的url进行继续的爬取工作使用CrawlSpider更合适。
CrawlSpider源码分析
源码解析
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
# 首先调用parse()来处理start_urls中返回的response对象
# parse()则将这些response对象传递给了_parse_response()函数处理,并设置回调函数为parse_start_url()
# 设置了跟进标志位True
# parse将返回item和跟进了的Request对象
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
# 处理start_url中返回的response,需要重写
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
# 从response中抽取符合任一用户定义'规则'的链接,并构造成Resquest对象返回
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
# 抽取之内的所有链接,只要通过任意一个'规则',即表示合法
for n, rule in enumerate(self._rules):
links = [l for l in rule.link_extractor.extract_links(response) if l not in seen]
# 使用用户指定的process_links处理每个连接
if links and rule.process_links:
links = rule.process_links(links)
# 将链接加入seen集合,为每个链接生成Request对象,并设置回调函数为_repsonse_downloaded()
for link in links:
seen.add(link)
# 构造Request对象,并将Rule规则中定义的回调函数作为这个Request对象的回调函数
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=n, link_text=link.text)
# 对每个Request调用process_request()函数。该函数默认为indentify,即不做任何处理,直接返回该Request.
yield rule.process_request(r)
# 处理通过rule提取出的连接,并返回item以及request
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
# 解析response对象,会用callback解析处理他,并返回request或Item对象
def _parse_response(self, response, callback, cb_kwargs, follow=True):
# 首先判断是否设置了回调函数。(该回调函数可能是rule中的解析函数,也可能是 parse_start_url函数)
# 如果设置了回调函数(parse_start_url()),那么首先用parse_start_url()处理response对象,
# 然后再交给process_results处理。返回cb_res的一个列表
if callback:
#如果是parse调用的,则会解析成Request对象
#如果是rule callback,则会解析成Item
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
# 如果需要跟进,那么使用定义的Rule规则提取并返回这些Request对象
if follow and self._follow_links:
#返回每个Request对象
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, basestring):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
CrawlSpider爬虫文件字段介绍
CrawlSpider除了继承Spider类的属性:name、allow_domains之外,还提供了一个新的属性:rules。它是包含一个或多个Rule对象的集合。每个Rule对爬取网站的动作定义了特定规则。如果多个Rule匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。
CrawlSpider也提供了一个可复写的方法:
parse_start_url(response)
当start_url的请求返回时,该方法被调用。该方法分析最初的返回值并必须返回一个Item对象或一个Request对象或者一个可迭代的包含二者的对象。
注意:当编写爬虫规则时,请避免使用parse 作为回调函数。 由于CrawlSpider使用parse 方法来实现其逻辑,如果 您覆盖了parse 方法,CrawlSpider将会运行失败。
另外,CrawlSpider还派生了其自己独有的更加强大的特性和功能,最显著的功能就是”LinkExtractors链接提取器“。
LinkExtractor
class scrapy.linkextractors.LinkExtractor
LinkExtractor是从网页(scrapy.http.Response)中抽取会被follow的链接的对象。目的很简单: 提取链接。每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象
即Link Extractors要实例化一次,并且 extract_links 方法会根据不同的 response 调用多次提取链接。源码如下:
class scrapy.linkextractors.LinkExtractor(
allow = (), # 满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
deny = (), # 与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。
allow_domains = (), # 会被提取的链接的domains。
deny_domains = (), # 一定不会被提取链接的domains。
deny_extensions = None,
restrict_xpaths = (), # 使用xpath表达式,和allow共同作用过滤链接
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
作用:提取response中符合规则的链接。
参考链接:https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/link-extractors.html
Rule类
LinkExtractor是用来提取的类,但是提取的规则需要通过Rule类实现。Rule类的定义如下:
class scrapy.contrib.spiders.Rule(link_extractor,callback=None,cb_kwargs=None,
follow=None,process_links=None,process_request=None)
参数如下:
link_extractor:是一个Link Extractor对象。其定义了如何从爬取到的页面提取链接。
callback:是一个callable或string(该Spider中同名的函数将会被调用)。从link_extractor中每获取到链接时将会调用该函数。该回调函数接收一个response作为其第一个参数,并返回一个包含Item以及Request对象(或者这两者的子类)的列表。
cb_kwargs:包含传递给回调函数的参数(keyword argument)的字典。
follow:是一个boolean值,指定了根据该规则从response提取的链接是否需要跟进。如果callback为None,follow默认设置True,否则默认False。
processlinks:是一个callable或string(该Spider中同名的函数将会被调用)。从linkextrator中获取到链接列表时将会调用该函数。该方法主要是用来过滤。
processrequest:是一个callable或string(该spider中同名的函数都将会被调用)。该规则提取到的每个request时都会调用该函数。该函数必须返回一个request或者None。用来过滤request。
参考链接:https://scrapy-chs.readthedocs.io/zhCN/latest/topics/spiders.html#topics-spiders-ref
通用爬虫案例
CrawlSpider整体的爬取流程:
爬虫文件首先根据url,获取该url的网页内容
链接提取器会根据提取规则,对步骤1网页内容中的链接进行提取
规则解析器会根据指定的解析规则,将链接提取器中提取到的链接按照指定的规则进行解析
将3中解析的数据封装到item中,最后提交给管道进行持久化存储
创建CrawlSpider爬虫项目
创建scrapy工程:scrapy startproject projectName
创建爬虫文件(切换到创建的项目下执行):scrapy genspider -t crawl spiderName www.xxx.com
--此指令对比以前的指令多了 "-t crawl",表示创建的爬虫文件是基于CrawlSpider这个类的,而不再是Spider这个基类。
启动爬虫文件(基于步骤二的路径执行):scrapy crawl crawlDemo
案例(爬取小说案例)
测试小说是否可用
本案例是17k小说网小说爬取,打开首页---->选择:分类---->选择:已完本、只看免费,如下图:
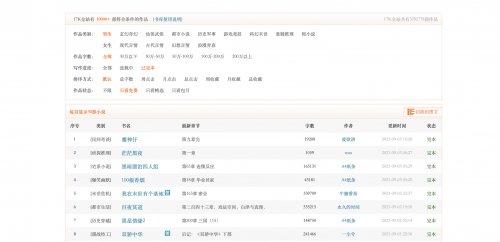
链接:https://www.17k.com/all/book/200030101.html
按照上面的步骤我们依次:
scrapy startproject seventeen_k
scrapy genspider -t crawl novel www.17k.com
Pycharm 打开项目
查看novel.py
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(allow = LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',follow=True, process_links="process_booklink"),
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("限制一本书:", link.url)
yield link
else:
return
def parse_book(self, response):
item = {
return item
首先测试一下是否可以爬取到内容,注意rules给出的规则:
Rule(allow = LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrictxpaths=('//td[@class="td3"]')),
callback='parsebook',follow=True, processlinks="processbooklink")
在allow中指定了提取链接的正则表达式,相当于findall(r'正则内容',response.text),在LinkExtractor中添加了参数restrict_xpaths是为了与正则表达式搭配使用,更快的定位链接。
callback='parse_item'是指定回调函数
process_links用于处理LinkExtractor匹配到的链接的回调函数
然后,配置settings.py里的必要配置后运行,即可发现指定页面第一本小说URL获取正常:
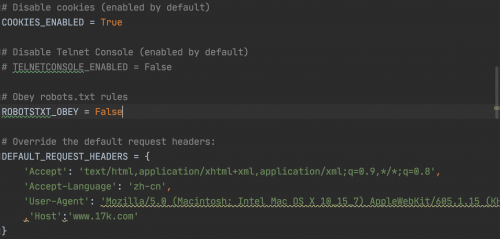
执行:scrapy crawl novel ,运行结果:
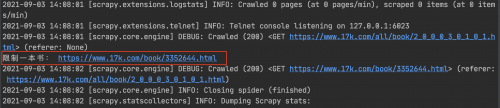
解析小说的详细信息
上图链接对应小说的详情页: https://www.17k.com/book/3352644.html
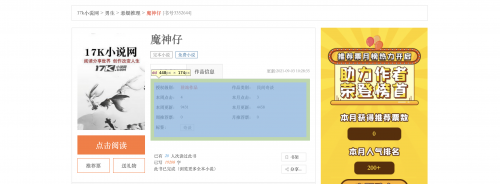
通过解析书籍的URL的获取到的响应,获取以下数据:
catagory(分类),bookname,status,booknums,description,ctime,bookurl,chapter_url
改写parse_book函数内容如下:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')), callback='parse_book',
follow=True, process_links="process_booklink"),
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("限制一本书:", link.url)
yield link
else:
return
def parse_book(self, response):
item ={}
print("解析book_url")
# 字数:
book_nums = response.xpath('//div[@class="BookData"]/p[2]/em/text()').extract()[0]
# 书名:
book_name = response.xpath('//div[@class="Info "]/h1/a/text()').extract()[0]
# 分类
category = response.xpath('//dl[@id="bookInfo"]/dd/div[2]/table//tr[1]/td[2]/a/text()').extract()[0]
# 概述
description = "".join(response.xpath('//p[@class="intro"]/a/text()').extract())
# 小说链接
book_url = response.url
# 小说章节
chapter_url = response.xpath('//dt[@class="read"]/a/@href').extract()[0]
print(book_nums, book_url,book_name,category,description,chapter_url)
return item
打印结果:
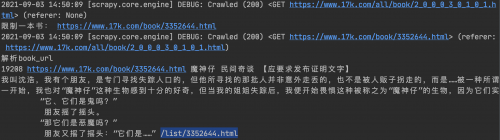
解析章节信息
通过解析书籍的URL获取的响应里解析得到每个小说章节列表页的URL,并发送请求获得响应,得到对应小说的章节列表页,获取以下数据:id , title(章节名称) content(内容),ordernum(序号),ctime,chapterurl(章节url),catalog_url(目录url)
在novel.py的rules中添加:
...
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',
follow=True, process_links="process_booklink"),
# 匹配章节目录的url
Rule(LinkExtractor(allow=r'/list/\d+.html',
restrict_xpaths=('//dt[@class="read"]')), callback='parse_chapter', follow=True,
process_links="process_chapterlink"),
)
def process_chapterlink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("章节:", link.url)
yield link
else:
return
...
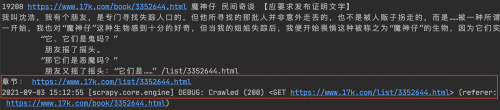
通过上图可以发现从上一个链接的response中,匹配第二个rule可以提取到章节的链接,继续编写解析章节详情的回调函数parse_chapter,代码如下:
# 前面代码省略
......
def parse_chapter(self, response):
print("解析章节目录", response.url) # response.url就是数据的来源的url
# 注意:章节和章节的url要一一对应
a_tags = response.xpath('//dl[@class="Volume"]/dd/a')
chapter_list = []
for index, a in enumerate(a_tags):
title = a.xpath("./span/text()").extract()[0].strip()
chapter_url = a.xpath("./@href").extract()[0]
ordernum = index + 1
c_time = datetime.datetime.now()
chapter_url_refer = response.url
chapter_list.append([title, ordernum, c_time, chapter_url, chapter_url_refer])
print('章节目录:', chapter_list)
重新运行测试,发现数据获取正常!
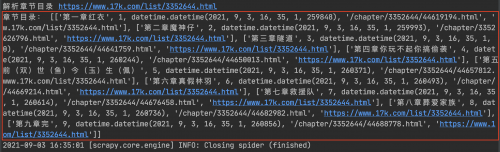
获取章节详情
通过解析对应小说的章节列表页获取到每一章节的URL,发送请求获得响应,得到对应章节的章节内容,同样添加章节的rule和回调函数.完整代码如下:
import datetime
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',
follow=True, process_links="process_booklink"),
# 匹配章节目录的url
Rule(LinkExtractor(allow=r'/list/\d+.html',
restrict_xpaths=('//dt[@class="read"]')), callback='parse_chapter', follow=True,
process_links="process_chapterlink"),
# 解析章节详情
Rule(LinkExtractor(allow=r'/chapter/(\d+)/(\d+).html',
restrict_xpaths=('//dl[@class="Volume"]/dd')), callback='get_content',
follow=False, process_links="process_chapterDetail"),
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("限制一本书:", link.url)
yield link
else:
return
def process_chapterlink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("章节:", link.url)
yield link
else:
return
def process_chapterDetail(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("章节详情:", link.url)
yield link
else:
return
def parse_book(self, response):
print("解析book_url")
# 字数:
book_nums = response.xpath('//div[@class="BookData"]/p[2]/em/text()').extract()[0]
# 书名:
book_name = response.xpath('//div[@class="Info "]/h1/a/text()').extract()[0]
# 分类
category = response.xpath('//dl[@id="bookInfo"]/dd/div[2]/table//tr[1]/td[2]/a/text()').extract()[0]
# 概述
description = "".join(response.xpath('//p[@class="intro"]/a/text()').extract())
# 小说链接
book_url = response.url
# 小说章节
chapter_url = response.xpath('//dt[@class="read"]/a/@href').extract()[0]
print(book_nums, book_url, book_name, category, description, chapter_url)
def parse_chapter(self, response):
print("解析章节目录", response.url) # response.url就是数据的来源的url
# 注意:章节和章节的url要一一对应
a_tags = response.xpath('//dl[@class="Volume"]/dd/a')
chapter_list = []
for index, a in enumerate(a_tags):
title = a.xpath("./span/text()").extract()[0].strip()
chapter_url = a.xpath("./@href").extract()[0]
ordernum = index + 1
c_time = datetime.datetime.now()
chapter_url_refer = response.url
chapter_list.append([title, ordernum, c_time, chapter_url, chapter_url_refer])
print('章节目录:', chapter_list)
def get_content(self, response):
content = "".join(response.xpath('//div[@class="readAreaBox content"]/div[@class="p"]/p/text()').extract())
print(content)
同样发现数据是正常的,如下图:
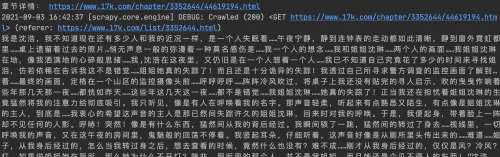
进行数据的持久化,写入Mysql数据库
a. 定义结构化字段(items.py文件的编写):
class Seventeen_kItem(scrapy.Item):
'''匹配每个书籍URL并解析获取一些信息创建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
category = scrapy.Field()
book_name = scrapy.Field()
book_nums = scrapy.Field()
description = scrapy.Field()
book_url = scrapy.Field()
chapter_url = scrapy.Field()
class ChapterItem(scrapy.Item):
'''从每个小说章节列表页解析当前小说章节列表一些信息所创建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
chapter_list = scrapy.Field()
class ContentItem(scrapy.Item):
'''从小说具体章节里解析当前小说的当前章节的具体内容所创建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
chapter_detail_url = scrapy.Field()
b. 编写novel.py
import datetime
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sevencat.items import Seventeen_kItem, ChapterItem, ContentItem
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html']
rules = (
Rule(LinkExtractor(allow=r'//www.17k.com/book/\d+.html', restrict_xpaths=('//td[@class="td3"]')),
callback='parse_book',
follow=True, process_links="process_booklink"),
# 匹配章节目录的url
Rule(LinkExtractor(allow=r'/list/\d+.html',
restrict_xpaths=('//dt[@class="read"]')), callback='parse_chapter', follow=True,
process_links="process_chapterlink"),
# 解析章节详情
Rule(LinkExtractor(allow=r'/chapter/(\d+)/(\d+).html',
restrict_xpaths=('//dl[@class="Volume"]/dd')), callback='get_content',
follow=False, process_links="process_chapterDetail"),
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("限制一本书:", link.url)
yield link
else:
return
def process_chapterlink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("章节:", link.url)
yield link
else:
return
def process_chapterDetail(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("章节详情:", link.url)
yield link
else:
return
def parse_book(self, response):
print("解析book_url")
# 字数:
book_nums = response.xpath('//div[@class="BookData"]/p[2]/em/text()').extract()[0]
# 书名:
book_name = response.xpath('//div[@class="Info "]/h1/a/text()').extract()[0]
# 分类
category = response.xpath('//dl[@id="bookInfo"]/dd/div[2]/table//tr[1]/td[2]/a/text()').extract()[0]
# 概述
description = "".join(response.xpath('//p[@class="intro"]/a/text()').extract())
# # 小说链接
book_url = response.url
# 小说章节
chapter_url = response.xpath('//dt[@class="read"]/a/@href').extract()[0]
# print(book_nums, book_url, book_name, category, description, chapter_url)
item = Seventeen_kItem()
item['book_nums'] = book_nums
item['book_name'] = book_name
item['category'] = category
item['description'] = description
item['book_url'] = book_url
item['chapter_url'] = chapter_url
yield item
def parse_chapter(self, response):
print("解析章节目录", response.url) # response.url就是数据的来源的url
# 注意:章节和章节的url要一一对应
a_tags = response.xpath('//dl[@class="Volume"]/dd/a')
chapter_list = []
for index, a in enumerate(a_tags):
title = a.xpath("./span/text()").extract()[0].strip()
chapter_url = a.xpath("./@href").extract()[0]
ordernum = index + 1
c_time = datetime.datetime.now()
chapter_url_refer = response.url
chapter_list.append([title, ordernum, c_time, chapter_url, chapter_url_refer])
# print('章节目录:', chapter_list)
item = ChapterItem()
item["chapter_list"] = chapter_list
yield item
def get_content(self, response):
content = "".join(response.xpath('//div[@class="readAreaBox content"]/div[@class="p"]/p/text()').extract())
chapter_detail_url = response.url
# print(content)
item = ContentItem()
item["content"] = content
item["chapter_detail_url"] = chapter_detail_url
yield item
c. 编写管道文件:
import pymysql
import logging
from .items import Seventeen_kItem, ChapterItem, ContentItem
logger = logging.getLogger(__name__) # 生成以当前文件名命名的logger对象。 用日志记录报错。
class Seventeen_kPipeline(object):
def open_spider(self, spider):
# 连接数据库
data_config = spider.settings["DATABASE_CONFIG"]
if data_config["type"] == "mysql":
self.conn = pymysql.connect(**data_config["config"])
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 写入数据库
if isinstance(item, Seventeen_kItem):
# 写入书籍信息
sql = "select id from novel where book_name=%s and author=%s"
self.cursor.execute(sql, (item["book_name"], ["author"]))
if not self.cursor.fetchone(): # .fetchone()获取上一个查询结果集。在python中如果没有则为None
try:
# 如果没有获得一个id,小说不存在才进行写入操作
sql = "insert into novel(category,book_name,book_nums,description,book_url,chapter_url)" \
"values(%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (
item["category"],
item["book_name"],
item["book_nums"],
item["description"],
item["book_url"],
item["catalog_url"],
))
self.conn.commit()
except Exception as e: # 捕获异常并日志显示
self.conn.rollback()
logger.warning("小说信息错误!url=%s %s") % (item["book_url"], e)
return item
elif isinstance(item, ChapterItem):
# 写入章节信息
try:
sql = "insert into chapter (title,ordernum,c_time,chapter_url,chapter_url_refer)" \
"values(%s,%s,%s,%s,%s)"
# 注意:此处item的形式是! item["chapter_list"]====[(title,ordernum,c_time,chapter_url,chapter_url_refer)]
chapter_list = item["chapter_list"]
self.cursor.executemany(sql,
chapter_list) # .executemany()的作用:一次操作,写入多个元组的数据。形如:.executemany(sql,[(),()])
self.conn.commit()
except Exception as e:
self.conn.rollback()
logger.warning("章节信息错误!%s" % e)
return item
elif isinstance(item, ContentItem):
try:
sql = "update chapter set content=%s where chapter_url=%s"
content = item["content"]
chapter_detail_url = item["chapter_detail_url"]
self.cursor.execute(sql, (content, chapter_detail_url))
self.conn.commit()
except Exception as e:
self.conn.rollback()
logger.warning("章节内容错误!url=%s %s") % (item["chapter_url"], e)
return item
def close_spider(self, spider):
# 关闭数据库
self.cursor.close()
self.conn.close()
其中涉及到settings.py的配置:
DATABASE_CONFIG={
"type":"mysql",
"config":{
"host":"localhost",
"port":3306,
"user":"root",
"password":"root",
"db":"noveldb",
"charset":"utf8"
}
}
数据库的表分别为:
novel表字段有:
id(自动增长的)
category
book_name
book_nums
description
book_url
chapter_url
chapter表字段有:
id
title
ordernum
c_time
chapter_url
chapter_url_refer
conent
如果想获取多页的小说则需要加入对start_urls处理的函数,通过翻页观察每页URL的规律,在此函数中拼接得到多页 的URL,并将请求发送给引擎!
......
page_num = 1
#start_urls的回调函数
# 作用:拼接得到每页小说的url。实现多页小说获取。
def parse_start_url(self, response):
print(self.page_num,response)
#可以解析star_urls的response 相当于之前的parse函数来用
#拼接下一页的url
self.page_num+=1
next_pageurl='https://www.17k.com/all/book/2_0_0_0_3_0_1_0_{}.html'.format(self.page_num)
if self.page_num==3:
return
yield scrapy.Request(next_pageurl)
注意:在每个对应的processxxxx的回调函数中都是获取index=0的小说,文章等,可以修改比如processchapterlink中的index<=20,那就是更多的章节信息了。
ok抓紧时间测试一下吧!相信你会收获很多!








