20天学会爬虫之Scrapy框架中间件

本次继续介绍Scrapy框架部分,本篇文章的主要内容是Middleware中间件,放心后面的案例也是必不可少的啦。下面这个图大家还记得吗?
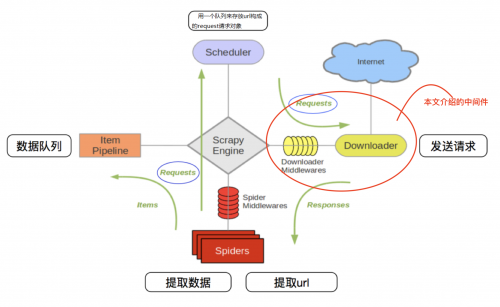
中间件是Scrapy里面的一个核心概念。使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫。
中间件这个中文名字和中间人只有一字之差。但是它们做的事情确实也非常相似。中间件可以在中途劫持数据,做一些修改再把数据传递出去,就像是中介一样。不同点在于,中间件是开发者主动加进去的组件,而中间人是被动的,有时可能是恶意地加进去的环节。
scrapy框架的中间件主要有两个,一个是spiderMiddleware(爬虫中间件),一个是DownloaderMiddleware(下载中间件)。通常由于在请求对象和响应对象数据,在下载中间件就能处理好,所以一般不会去使用爬虫中间件。因此我们首先来看一下DownloaderMiddleware(下载中间件)
下载中间件
下载中间件的作用就是:
引擎engine将request对象交给下载器之前,会经过下载器中间件;此时,中间件提供了一个方法 process_request,可以对 request对象进行设置随机请求头、IP代理、Cookie等;
当下载器完成下载时,获得到 response对象,将它交给引擎engine的过程中,再一次经过 下载器中间件;此时,中间件提供了另一个方法 process_response;可以判断 response对象的状态码,来决定是否将 response提交给引擎。
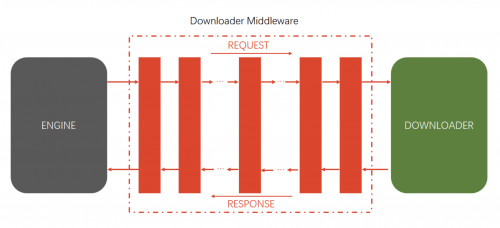
下载中间件主要用到的方法有三个:
process_request:用来处理正常的请求对象的数据,每个request请求通过下载中间件时,该方法被调用。
process_response:用来处理响应对象的数据
process_exception:用来处理抛异常的请求对象的数据
其他的初始化类的对象的方法及打开日志的方法可有可无。
process_request(self,request,spider)下载器在发送请求之前会执行的,一般可以在这个里面设置随机代理 ip 等
参数:
request:发送请求的 request 对象
spider:发送请求的 spider 对象
返回值有可能会返回下面的任何一种:
返回 None:如果返回 None,Scrapy 将继续处理该 request,执行其他中间件中的相应方法,直到合适的下载器处理函数被调用
返回 Response 对象:Scrapy 将不会调用任何其他的 processrequest 方法,将直接返回这个 response 对象,已经激活的中间件的 processresponse() 方法则会在每个 response 返回时被调用
返回 Request 对象:Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。
process_response(self,request,response,spider)下载器下载的数据到引擎中间会执行的方法。
参数:
request:request 对象
response:被处理的 response 对象
spider:spider 对象
返回值可能会返回如下几种:
返回 Response 对象,会将这个新的 response 对象传给其他中间件,最终传给爬虫
返回 Request 对象:下载器链被切断,返回的 request 会重新被下载器调度下载。
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
process_exception(request, exception, spider)
返回值返回以下之一: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
返回Response 对象,则已安装的中间件链的 processresponse() 方法被调用。Scrapy将不会调用任何其他中间件的 processexception() 方法。
返回 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。
熟悉了这三个方法,基本上可以写出,UA、Cookie、代理、Selenium中间件了。
案例
随机请求头中间件
爬虫在频繁访问一个页面的时候,这个请求头如果一直保持一致,那么很容易被服务器发现,从而禁止掉这个请求头的访问,因此我们要在访问这个页面之前随机的更改请求头,这样可以避免爬虫被抓,随即更改请求头,可以在下载中间件中实现,在请求发送给服务器之前,随机的选择一个请求头,这样就可以避免总使用一个请求头。
我们以豆瓣同城为例带领大家学习简单使用。
首先创建项目:scrapy startproject doubanSpider,并创建tongcheng爬虫:scrapy genspider tongcheng beijing.douban.com
爬虫代码如下:
import scrapy
class TongchengSpider(scrapy.Spider):
name = 'tongcheng'
allowed_domains = ['beijing.douban.com']
start_urls = ['https://beijing.douban.com/events/week-all']
def parse(self, response):
print(f"请求头信息为: {response.request.headers.get('User-Agent')}")
打开项目中的middleware.py文件,然后修改里面DoubanspiderDownloaderMiddleware类的process_request方法,内容如下:
import random
from doubanSpider.settings import USER_AGENT_LIST
class DoubanspiderDownloaderMiddleware:
...
def process_request(self, request, spider):
ua = random.choice(USER_AGENT_LIST)
request.headers['User-Agent'] = ua
...
上面代码涉及到的USERAGENTLIST是在settings.py设置文件中,在原有的内容中添加USERAGENTLIST(常见的请求头)
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
]
当然也可以在http://www.useragentstring.com/pages/useragentstring.php?typ=Browser网址获取一些请求头。
注意此时还要设置里面的DOWNLOADERMIDDLEWARES,默认是有的把注释取消掉就可以了。以及将里面的ROBOTSTXTOBEY设置成False,哈哈不遵守网站的robots.txt 的规则了,另外如果不需要模拟登陆也要将COOKIESENABLED ( Cookies中间件) 设置禁用状态。COOKIESENABLED = False
DOWNLOADER_MIDDLEWARES = {
'doubanSpider.middlewares.DoubanspiderDownloaderMiddleware': 543,
}
COOKIES_ENABLED = False
ROBOTSTXT_OBEY = False
宋宋发现很多文章建议使用fake-useragent 模块,安装:pip install fake-useragent,但是宋宋测试发现:
from fake_useragent import UserAgent
ua = UserAgent()
print(ua.random)
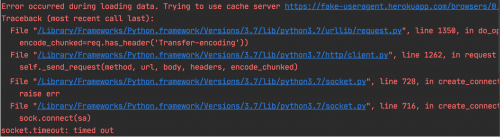
报错连接超时,当然在Scrapy中也测试失败---连接超时,所以不建议大家使用。(最后一次更新是2018年,后来一直没有更新了)
运行爬虫文件我们发现:scrapy crawl tongcheng

代理ip的使用
使用代理 IP 实现网络爬虫是有效解决反爬虫的一种方法,获取代理IP的方式可以去这几个网站获取:
http://www.goubanjia.com/
https://www.kuaidaili.com/free/
http://www.ip3366.net/
https://ip.jiangxianli.com/?page=1
https://www.dieniao.com/FreeProxy/1.html
http://http.zhiliandaili.cn/
为了更加快速的获取IP并检测每个IP的有效性,可以参考下面的代码测试(只是展示了一个网站的数据,还有其他的获取思路是一样的)
import requests # 导入网络请求模块
from lxml import etree # 导入 HTML 解析模块
import pandas as pd # 导入pandas模块
import urllib3
urllib3.disable_warnings()
ip_list = [] # 创建保存有效IP地址的列表
# 头部信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
def get_ip(url, headers):
response = requests.get(url=url, headers=headers, verify=False)
response.encoding = "utf8" # 设置编码方式
if response.status_code == 200: # 判断请求是否成功
html = etree.HTML(response.text) # 解析HTML
# 获取所有带有IP的li标签
li_list = html.xpath('//div[@class="container"]/div[2]/ul/li')[1:]
for li in li_list: # 遍历每行内容
ip = li.xpath('./span[@class="f-address"]/text()')[0] # 获取ip
port = li.xpath('./span[@class="f-port"]/text()')[0] # 获取端口
ip = ip + ":" + port
proxies = {'http': 'http://{ip}'.format(ip=ip),
'https': 'https://{ip}'.format(ip=ip)}
try:
response = requests.get(
"https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=ip",
headers=headers, timeout=3, proxies=proxies)
if response.status_code == 200: # 判断是否请求成功,请求成功说明代理IP可用
response.encoding = "utf8" # 进行编码
html = etree.HTML(response.text) # 解析HTML
info = html.xpath('//*[@id="1"]/div[1]/div[1]/div[2]/table//tr/td//text()')[1:]
info = " ".join(info).replace("\xa0", "").strip().replace("本机IP:", "本机IP: ")
print(info) # 输出当前IP匿名信息
if info:
ip_list.append(info)
except Exception as e:
# print(e) # 打印异常信息
pass
if __name__ == '__main__':
ip_table = pd.DataFrame(columns=["ip"]) # 创建临时表格
for i in range(1, 5):
# 构造免费代理IP的请求地址
url = "https://www.dieniao.com/FreeProxy/{}.html".format(i)
get_ip(url, headers)
print(ip_list)
有了上一步我们就可以轻松的获取一些免费的IP地址了。这种免费IP很容易过期,所以建议大家可以去购买私密代理。
PROXIES = [
'121.232.148.181:3256',
'118.117.188.215:3256',
'121.232.148.195:3256'
]
于是在 Scrapy 中简单地应用一次代理 IP 时可以使用以下代码,在middleware.py中添加ProxyMiddleWare类
class ProxyMiddleWare(object):
def process_request(self, request, spider):
try:
proxy = random.choice(PROXIES)
request.meta['proxy'] = 'http://' + proxy
print('当前的代理ip为....', request.meta['proxy'])
except request.exceptions.RequestException:
spider.logger.error('some error happended!')
def process_exception(self, request, spider, exception):
print('代理失效了,换一个代理IP')
注意要在settings.py中设置此中间件,
DOWNLOADER_MIDDLEWARES = {
'doubanSpider.middlewares.DoubanspiderDownloaderMiddleware': 543,
'doubanSpider.middlewares.ProxyMiddleWare': 400,
}
如何确定中间件后面的数字应该怎么写呢?
数字越小的中间件越先执行,例如Scrapy自带的第1个中间件RobotsTxtMiddleware,它的作用是首先查看settings.py中ROBOTSTXT_OBEY这一项的配置是True还是False。如果是True,表示要遵守Robots.txt协议,它就会检查将要访问的网址能不能被运行访问,如果不被允许访问,那么直接就取消这一次请求,接下来的和这次请求有关的各种操作全部都不需要继续了。
开发者自定义的中间件,会被按顺序插入到Scrapy自带的中间件中。爬虫会按照从100~900的顺序依次运行所有的中间件。直到所有中间件全部运行完成,或者遇到某一个中间件而取消了这次请求。要禁用Scrapy的中间件,需要在settings.py里面将这个中间件的顺序设为None即可。
运行爬虫测试结果:scrapy crawl tongcheng
Spider Middleware 的用法
Spider Middleware是介入到Scrapy的Spider处理机制的钩子框架。如图
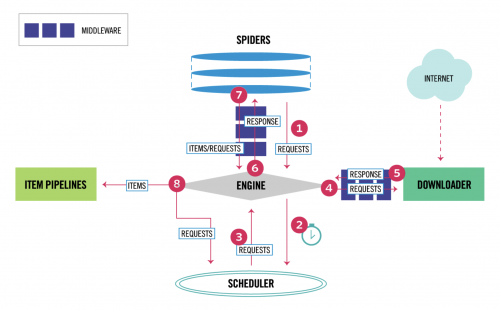
当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过Spider Middleware处理,当Spider处理生成Item和Request之后,Item和Request还会经过Spider Middleware的处理。
Spider Middleware有如下三个作用:
在Downloader生成的Response发送给Spider之前,也就是在Response发送给Spider之前对Response进行处理。
在Spider生成的Request发送给Scheduler之前,也就是在Request发送给Scheduler之前对Request进行处理。
在Spider生成的Item发送给Item Pipeline之前,也就是在Item发送给Item Pipeline之前对Item进行处理。
需要说明的是,Scrapy其实已经自带了了许多Spider Middleware,它们被SPIDERMIDDLEWARESBASE这个变量所定义。
SPIDERMIDDLEWARESBASE变量的内容如下:
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrllengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
和Downloader Middleware一样,Spider Middleware首先加入到SPIDERMIDDLEWARES设置中,该设置会和Scrapy中SPIDERMIDDLEWARES_BASE定义的Spider Middleware合并。然后根据键值的数字优先级排序,得到一个有序列表。第一个Middleware是最靠近引擎的,最后一个Middleware是最靠近Spider的。
Scrapy内置的Spider Middleware为Scrapy提供了基础的功能。如果我们想要扩展其功能,只需要实现某几个方法即可。
每个Spider Middleware都定义了以下一个或多个方法的类,核心方法有如下4个:
processspiderinput(response, spider):当Response被Spider Middleware处理时·,processspiderinput()方法被调用。参数有如下两个:response是被处理的Response对象。另一个是该Response对应的Spider。返回结果是:None或者抛出一个异常。
processspideroutput(response, result, spider):当Spider处理Response返回结果时,processspideroutput()方法被调用。参数有如下三个:
• response,是Response对象,即生成该输出的Response。
• result,包含Request或Item对象的可迭代对象,即Spider返回的结果。
• spider,是Spider对象,即其结果对应的Spider
必须返回包含Request或Item对象的可迭代对象
processspiderexception(response, exception, spider):当Spider或Spider Middleware的processspiderinput()方法抛出异常时,processspiderexception()方法被调用。返回值是要么返回None,要么返回一个包含Response或Item对象的可迭代对象
processstartrequests(start_requests, spider):processstartrequests()方法以Spider启动的Request为参数被调用,执行的过程类似于processspideroutput(),只不过它没有相关联的Response,并且必须返回Request。
说实话,Spider Middleware使用的频率不高,使用的绝大部分都是下载器中间件。所以就不给大家举例啦!
同时老师还给大家准备好了,完整的豆瓣同城的获取案例,包含爬虫、中间件、管道和数据库部分,可以联系客服领取哦。








