20天学会爬虫之Scrapy管道piplines

Item Pipline介绍
对于Item pipline我们前面已经简单的使用过了,更加详细的使用本文给大家一一道来。
在我们开始学习Item Pipline之前,我们还是来看一下下面这张图。
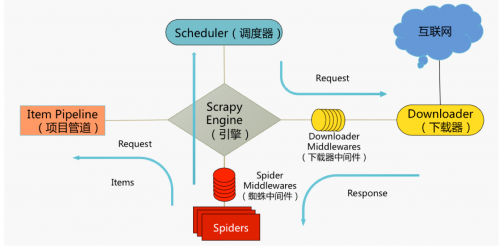
大家可以看到上图最左侧的就是Item Pipline。Item管道的主要任务就是负责处理有Spider从网页中抽取的Item,因此Item Pipline的主要任务就是清洗、验证和存储数据。 当页面被Spider解析后,将被发送到Item管道,Item Pipline获取了Items中的数据并执行对应的方法,并决定是否需要在Item管道中继续执行下一步或是直接丢弃掉不处理。
因此对于Item Pipline其主要的作用包括如下:
• 清理HTML数据。
• 验证爬取数据,检查爬取字段。
• 查重并丢弃重复内容。
• 将爬取结果保存到数据库。
核心方法介绍
Item管道主要有4个方法,分别是:
(1)open_spider(spider)
(2)close_spider(spider)
(3)from_crawler(cls,crawler)
(4)process_item(item,spider)
open_spider(spider)【参数spider 即被开启的Spider对象】
是在开启spider的时候触发的,常用于初始化操作(常见的有:开启数据库连接,打开文件等)。该方法非必需实现,可以根据需求定义。
close_spider(spider) 【参数spider 即被关闭的Spider对象】
是在 Spider 关闭的时候自动调用的,在这里我们可以做一些收尾工作,如关闭数据库连接等,该方法非必需实现,可以根据需求定义。
from_crawler(cls,crawler)【参数一:Class类 参数二:crawler对象】
该方法Spider启用时调用,比open_spider()方法调用还要早,是一个类方法,用@classmethod标识,是一种依赖注入的方式。它的参数有crawler,通过crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后创建一个Pipeline实例。参数cls就是Class,最后返回一个Class实例。
process_item(item,spider) 【参数一:被处理的Item对象 参数二:生成该Item的Spider对象】
该方法是必须要实现的方法,被定义的 Item Pipeline 会默认调用这个方法对 Item 进行处理。比如,我们可以进行数据处理或者将数据写入到数据库等操作。它必须返回 Item 类型的值或者抛出一个 DropItem 异常。
• 如果返回的是 Item 对象,那么此 Item 会接着被低优先级的 Item Pipeline 的 process_item () 方法进行处理,直到所有的方法被调用完毕。
• 如果抛出的是 DropItem 异常,那么此 Item 就会被丢弃,不再进行处理。
延伸扩展:ImagesPipline
爬虫程序爬取的目标通常不仅仅是文字资源,经常也会爬取图片资源。这就涉及如何高效下载图片的问题。这里高效下载指的是既能把图片完整下载到本地又不会对网站服务器造成压力。此时你可以不在 pipeline 中自己实现下载图片逻辑,可以通过 Scrapy 提供的图片管道ImagesPipeline,这样可以更加高效的操作下载图片。
ImagesPipeline 具有以下特点:
• 将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
• 避免重新下载最近已经下载过的图片
• 缩略图生成
• 检测图像的宽/高,确保它们满足最小限制
使用说明:
在pipline.py中可以新定义一个类,比如:xxImagePipline,Scrapy 默认生成的类是继承Object, 要将该类修改为继承ImagesPipeline。然后实现get_media_requests和item_completed这两个函数
其中,get_media_requests函数为每个 url 生成一个 Request。而item_completed(self, results, item, info)当一个单独项目中的所有图片请求完成时,该方法会被调用。
处理结果会以二元组的方式返回给 item_completed() 函数,即参数:results。
results参数二元组结果是:(success, imageinfoorfailure)
其中success表示图片是否下载成功;imageinfoorfailure是一个字典,包含三个属性:
url - 图片下载的url。这是从 getmediarequests() 方法返回请求的url。
path - 图片存储的路径(类似 IMAGES_STORE)
checksum - 图片内容的 MD5 hash
如果需要file_path(request, response=None, info=None)
request表示当前下载对应的request对象(request.dict查看属性),该方法用来返回文件名
response返回的是None
info一样的返回是一个对象(info.dict查看)
同时需要结合settings.py的配置进行设置,比如设置配置存放图片的路径以及自定义下载的图片管道。
# 可以避免下载最近已经下载的图片,90天的图片失效期限
IMAGES_EXPIRES = 90
IMAGES_STORE = '设置存放图片的路径'
# 如果需要也可以设置缩略图
# IMAGES_THUMBS = {
# 'small': (50, 50), # (宽, 高)
# 'big': (270, 270),
# }
# 配置自定义下载的图片管道, 默认是被注释的
ITEM_PIPELINES = {
# yourproject.middlewares(文件名).middleware类
'项目名.pipelines.xxImagePipeline': 数值,
}
并且Scrapy 框架下载图片会用到这个Python Imaging Library (PIL)图片加载库,所以也要提前安装好这个库。
pip install pillow
案例
本次我们爬取的网站是一个有很多治愈系图片的网站,更加重要的是免费的。链接是:http://www.designerspics.com

我们要实现的在MongoDB中存储,图片的名字和下载地址,并将图片下载到本地。因为我们前面存储没有使用过MongoDB或者Redis等非关系型数据库,所以本次案例我们使用MongoDB存储。
首先新建一个项目,命令如下:
scrapy startproject designerspics
接下来新建一个 Spider,命令如下:
scrapy genspider designer www.designerspics.com
这样我们就成功创建了一个 Spider。
接下来使用PyCharm打开爬虫项目,开始编写爬虫。
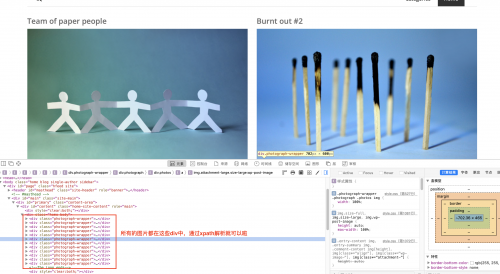
于是我们的爬虫代码就是(当然现在爬取的只是第一页,如果是多页爬取则需要重写start_requests(self)方法):
import scrapy
from designerspics.items import DesignerspicsItem
class DesignerSpider(scrapy.Spider):
name = 'designer'
allowed_domains = ['www.designerspics.com']
start_urls = ['http://www.designerspics.com/']
def parse(self, response):
title = response.xpath('//div[@class="photograph-wrapper"]/div/h5[1]/text()').extract()
image_url = response.xpath('//div[@class="photograph-wrapper"]/div/div/a/img/@src').extract()
for index, t in enumerate(title):
item = DesignerspicsItem()
item['title'] = t[2:]
item['image_url'] = image_url[index]
yield item
如果多页爬取则可以这样写,因为每一页的地址是这样的除了第一页
第一页:http://www.designerspics.com/
第二页:http://www.designerspics.com/page/2/
第三页:http://www.designerspics.com/page/3/
...
import scrapy
from scrapy import Request
from designerspics.items import DesignerspicsItem
class DesignerSpider(scrapy.Spider):
name = 'designer'
allowed_domains = ['www.designerspics.com']
# start_urls = ['http://www.designerspics.com/']
def start_requests(self):
# 爬取10页内容
for i in range(1, 11):
if i == 1:
url = "http://www.designerspics.com/"
yield Request(url, self.parse)
else:
url = 'http://www.designerspics.com/page/' + str(i)+"/"
yield Request(url, self.parse)
def parse(self, response):
title = response.xpath('//div[@class="photograph-wrapper"]/div/h5[1]/text()').extract()
image_url = response.xpath('//div[@class="photograph-wrapper"]/div/div/a/img/@src').extract()
for index, t in enumerate(title):
item = DesignerspicsItem()
item['title'] = t[2:]
item['image_url'] = image_url[index]
yield item
其中DesignerspicsItem类的代码如下:
import scrapy
class DesignerspicsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
collection = 'designerimages'
title = scrapy.Field()
image_url = scrapy.Field()
此时开始定义Item Pipline,打开piplines.py文件
import pymongo
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class DesignerspicsPipeline:
def __init__(self, mongo_uri, mongo_db, mongo_port):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.mongo_port = mongo_port
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'),
mongo_port=crawler.settings.get('MONGO_PORT')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(host=self.mongo_uri, port=self.mongo_port)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['image_url'])
此时需要在settings.py中配置:
MONGO_URI = '127.0.0.1'
MONGO_DB = 'designerimages'
MONGO_PORT = 27017
# 需要设置存储图片的路径
IMAGES_STORE = './images'
启动爬虫:
scrapy crawl designer
来看一下成果吧!

Mongo数据库的数据展示一下:

下篇预告:Scrapy分布式,欢迎分享!!!








