60,000毫秒内对Linux进行性能诊断

当你发现 Linux 服务器上的系统性能问题,在最开始的 1 分钟时间里,你会查看哪些系统指标呢?
Netflix 在 AWS 上有着大规模的 EC2 集群,以及各种各样的性能分析和监控工具。比如我们使用 Atlas 来监控整个平台,用 Vector 实时分析 EC2 实例的性能。这些工具已经能够帮助我们解决大部分的问题,但是有时候我们还是要登录进机器内部,用一些标准的 Linux 性能分析工具来定位问题。

在这篇文章里,Netflix 性能工程团队会介绍一些我们使用的标准的 Linux 命令行工具,在发现问题的前 60 秒内去分析和定位问题。在这 60 秒内,你可以使用下面这 10 个命令行了解系统整体的运行情况,以及当前运行的进程对资源的使用情况。
在这些指标里面,我们先关注和错误、以及和资源饱和率相关的指标,然后再看资源使用率。相对来讲,错误和资源饱和率比较容易理解。饱和的意思是指一个资源(CPU,内存,磁盘)上的负载超过了它能够处理的能力,这时候我们观察到的现象就是请求队列开始堆积,或者请求等待的时间变长。

有些命令行依赖于 sysstat 包。通过这些命令行的使用,你可以熟悉一下分析系统性能问题时常用的一套方法或者流程:USE 。这个方法主要从资源使用率(Utilization)、资源饱和度(Satuation)、错误(Error),这三个方面对所有的资源进行分析(CPU,内存,磁盘等等)。在这个分析的过程中,我们也要时刻注意我们已经排除过的资源问题,以便缩小我们定位的范围,给下一步的定位提供更明确的方向。
下面的章节对每个命令行做了一个说明,并且使用了我们在生产环境的数据作为例子。对这些命令行更详细的描述,请查看相应的帮助文档。
1 uptime

这个命令能很快地检查系统平均负载,你可以认为这个负载的值显示的是有多少任务在等待运行。在 Linux 系统里,这包含了想要或者正在使用 CPU 的任务,以及在 io 上被阻塞的任务。这个命令能使我们对系统的全局状态有一个大致的了解,但是我们依然需要使用其它工具获取更多的信息。
这三个值是系统计算的 1 分钟、5 分钟、15 分钟的指数加权的动态平均值,可以简单地认为就是这个时间段内的平均值。根据这三个值,我们可以了解系统负载随时间的变化。比如,假设现在系统出了问题,你去查看这三个值,发现 1 分钟的负载值比 15 分钟的负载值要小很多,那么你很有可能已经错过了系统出问题的时间点。
在上面这个例子里面,负载的平均值显示 1 分钟为 30,比 15 分钟的 19 相比增长较多。有很多原因会导致负载的增加,也许是 CPU 不够用了;vmstat 或者 mpstat 可以进一步确认问题在哪里。
2 dmesg | tail

这个命令显示了最新的几条系统日志。这里我们主要找一下有没有一些系统错误会导致性能的问题。上面的例子包含了 oom-killer 以及 TCP 丢包。
不要略过这一步!dmesg 永远值得看一看。
3 vmstat 1
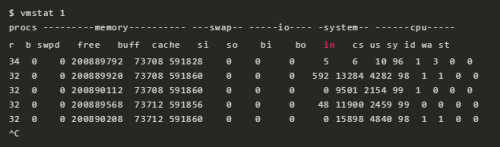
vmstat 展示了虚拟内存、CPU 的一些情况。上面这个例子里命令行的 1 表示每隔 1 秒钟显示一次。在这个版本的 vmstat 里,第一行表示了这一次启动以来的各项指标,我们可以暂时忽略掉第一行。
需要查看的指标:
r:处在 runnable 状态的任务,包括正在运行的任务和等待运行的任务。这个值比平均负载能更好地看出 CPU 是否饱和。这个值不包含等待 io 相关的任务。当 r 的值比当前 CPU 个数要大的时候,系统就处于饱和状态了。free:以 KB 计算的空闲内存大小。si,so:换入换出的内存页。如果这两个值非零,表示内存不够了。us,sy,id,wa,st:CPU 时间的各项指标(对所有 CPU 取均值),分别表示:用户态时间,内核态时间,空闲时间,等待 io,偷取时间(在虚拟化环境下系统在其它租户上的开销) 把用户态 CPU 时间(us)和内核态 CPU 时间(sy)加起来,我们可以进一步确认 CPU 是否繁忙。等待 IO 的时间 (wa)高的话,表示磁盘是瓶颈;注意,这个也被包含在空闲时间里面(id), CPU 这个时候也是空闲的,任务此时阻塞在磁盘 IO 上了。你可以把等待 IO 的时间(wa)看做另一种形式的 CPU 空闲,它可以告诉你 CPU 为什么是空闲的。
系统处理 IO 的时候,肯定是会消耗内核态时间(sy)的。如果内核态时间较多的话,比如超过 20%,我们需要进一步分析,也许内核对 IO 的处理效率不高。
在上面这个例子里,CPU 时间大部分都消耗在了用户态,表明主要是应用层的代码在使用 CPU。CPU 利用率 (us + sy)也超过了 90%,这不一定是一个问题;我们可以通过 r 和 CPU 个数确定 CPU 的饱和度。
4 mpstat -P ALL 1
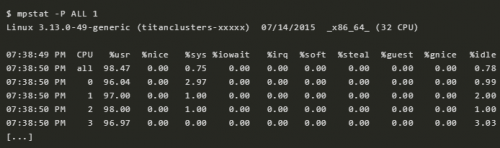
这个命令把每个 CPU 的时间都打印出来,可以看看 CPU 对任务的处理是否均匀。比如,如果某一单个 CPU 使用率很高的话,说明这是一个单线程应用。
5 pidstat 1
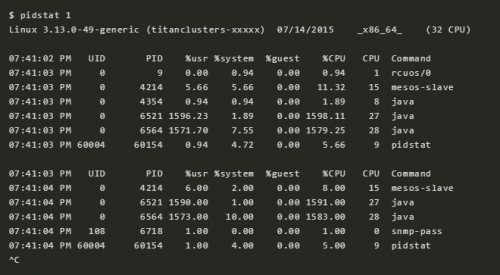
pidstat 和 top 很像,不同的是它可以每隔一个间隔打印一次,而不是像 top 那样每次都清屏。这个命令可以方便地查看进程可能存在的行为模式,你也可以直接 copy past,可以方便地记录随着时间的变化,各个进程运行状况的变化。
上面的例子说明有 2 个 Java 进程消耗了大量 CPU。这里的 %CPU 表明的是对所有 CPU 的值,比如 1591% 标识这个 Java 进程几乎消耗了 16 个 CPU。
6 iostat -xz 1
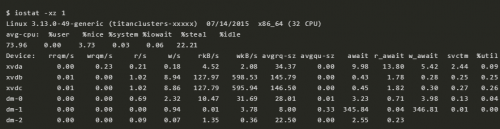
iostat 是理解块设备(磁盘)的当前负载和性能的重要工具。几个指标的含义:
r/s,w/s,rkB/s,wkB/s:系统发往设备的每秒的读次数、每秒写次数、每秒读的数据量、每秒写的数据量。这几个指标反映的是系统的工作负载。系统的性能问题很有可能就是负载太大。await:系统发往 IO 设备的请求的平均响应时间。这包括请求排队的时间,以及请求处理的时间。超过经验值的平均响应时间表明设备处于饱和状态,或者设备有问题。
avgqu-sz:设备请求队列的平均长度。队列长度大于 1 表示设备处于饱和状态。%util:设备利用率。设备繁忙的程度,表示每一秒之内,设备处理 IO 的时间占比。大于 60% 的利用率通常会导致性能问题(可以通过 await 看到),但是每种设备也会有有所不同。接近 100% 的利用率表明磁盘处于饱和状态。
如果这个块设备是一个逻辑块设备,这个逻辑快设备后面有很多物理的磁盘的话,100% 利用率只能表明有些 IO 的处理时间达到了 100%;后端的物理磁盘可能远远没有达到饱和状态,可以处理更多的负载。
还有一点需要注意的是,较差的磁盘 IO 性能并不一定意味着应用程序会有问题。应用程序可以有许多方法执行异步 IO,而不会阻塞在 IO 上面;应用程序也可以使用诸如预读取,写缓冲等技术降低 IO 延迟对自身的影响。
7 free -m

右边的两列显式:
buffers:用于块设备 I/O 的缓冲区缓存。cached:用于文件系统的页面缓存。我们只是想要检查这些不接近零的大小,其可能会导致更高磁盘 I/O(使用 iostat 确认),和更糟糕的性能。上面的例子看起来还不错,每一列均有很多 M 个大小。
比起第一行,-/+ buffers/cache 提供的内存使用量会更加准确些。Linux 会把暂时用不上的内存用作缓存,一旦应用需要的时候就立刻重新分配给它。所以部分被用作缓存的内存其实也算是空闲的内存。为了解释这一点, 甚至有人专门建了个网站:http://www.linuxatemyram.com/。
如果使用 ZFS 的话,可能会有点困惑。ZFS 有自己的文件系统缓存,在 free -m 里面看不到;系统看起来空闲内存不多了,但是有可能 ZFS 有很多的缓存可用。
8 sar -n DEV 1

这个工具可以查看网络接口的吞吐量:rxkB/s 和 txkB/s 可以测量负载,也可以看是否达到网络流量限制了。在上面的例子里,eth0 的吞吐量达到了大约 22 Mbytes/s,差不多 176 Mbits/sec ,比 1 Gbit/sec 还要少很多。
这个例子里也有 %ifutil 标识设备利用率,我们也用 Brenan 的 nicstat tool 测量。和 nicstat 一样,这个设备利用率很难测量正确,上面的例子里好像这个值还有点问题。
9 sar -n TCP,ETCP 1
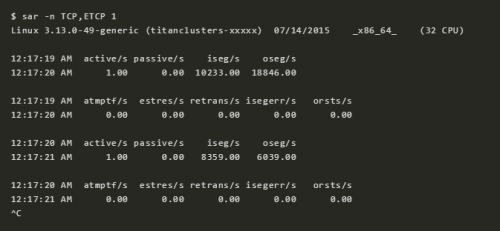
这是对 TCP 重要指标的一些概括,包括:
active/s:每秒钟本地主动开启的 TCP 连接,也就是本地程序使用 connect() 系统调用
passive/s:每秒钟从源端发起的 TCP 连接,也就是本地程序使用 accept() 所接受的连接
retrans/s:每秒钟的 TCP 重传次数
atctive 和 passive 的数目通常可以用来衡量服务器的负载:接受连接的个数(passive),下游连接的个数(active)。可以简单认为 active 为出主机的连接,passive 为入主机的连接;但这个不是很严格的说法,比如 loalhost 和 localhost 之间的连接。重传表示网络或者服务器的问题。也许是网络不稳定了,也许是服务器负载过重开始丢包了。上面这个例子表示每秒只有 1 个新连接建立。
10 top
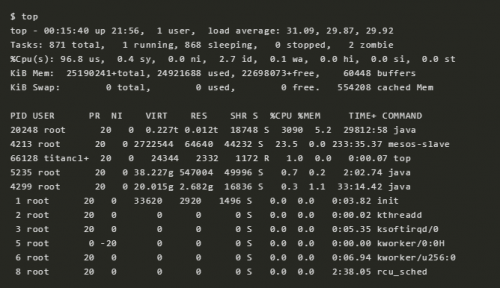
top 命令涵盖了我们前面讲述的许多指标。我们可以用它来看和我们之前查看的结果有没有很大的不同,如果有的话,那表示系统的负载在变化。
top 的缺点就是你很难找到这些指标随着时间的一些行为模式,在这种情况下,vmstat 或者 pidstat 这种可以提供滚动输出的命令是更好的方式。如果你不以足够快的速度暂停输出(Ctrl-S 暂停,Ctrl-Q 继续),一些间歇性问题的线索也可能由于被清屏而丢失。






