大数据面试题:经典面试题答疑(三)

大数据经典面试题答疑---经常问的原理问题总结(系列文章,持续更新),帮你解决大数据开发中的困扰。
1. hive+MapReduce
答案区:
1. hive+MapReduce
Hive不支持行级数据的插入、更新和删除,也不支持事务操作;
1.1. MapReduce的join过程

(1):利用DistributedCache将小表分发到各个节点上,在Map过程的setup()函数里,读取缓存里的文件,只将小表的连接键存储在hashSet中。
(2):在map()函数执行时,对每一条数据进行判断(包含小表数据),如果这条数据的连接键为空或者在hashSet里不存在,那么则认为这条数据无效,这条数据也不参与reduce的过程。
1.2. hive的SQL解析过程
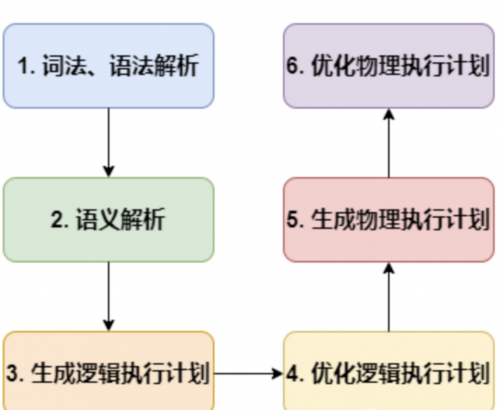
词法、语法解析: Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
语义解析: 遍历 AST Tree(抽象语法树,抽象语法结构的树状),抽象出查询的基本组成单元 QueryBlock;
生成逻辑执行计划: 遍历 QueryBlock,翻译为执行操作树 OperatorTree;
优化逻辑执行计划: 逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少 MapReduce Job,减少数据传输及 shuffle 数据量;
生成物理执行计划: 遍历 OperatorTree,翻译为 MapReduce 任务;
优化物理执行计划: 物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
1.3. hive数据导入
load data inpath '/hadoop/guozy/data/user.txt' into table external_table;
此处是移动(非复制),移动数据非常快,不会对数据是否符合定义的Schema做校验,这个工作通常在读取的时候进行(即Schema on Read)
1.4. 内部表与外部表的不同
1.创建外部表需要添加 external 字段。而内部表不需要。
2.删除外部表时,HDFS中的数据文件不会一起被删除。而删除内部表时,表数据及HDFS中的数据文件都会被删除。
3.内部表与外部表如果不指定location,默认使用hive.metastore.warehouse.dir指定的路径
1.5. 分区和分桶
1.5.1. 分区
指的就是将数据按照表中的某一个字段进行统一归类,并存储在表中的不同的位置,也就是说,一个分区就是一类,这一类的数据对应到hdfs存储上就是对应一个目录。
1.5.1.1. 静态分区
数据已经按某些字段分完区放在一块,建表时直接指定分区即可。
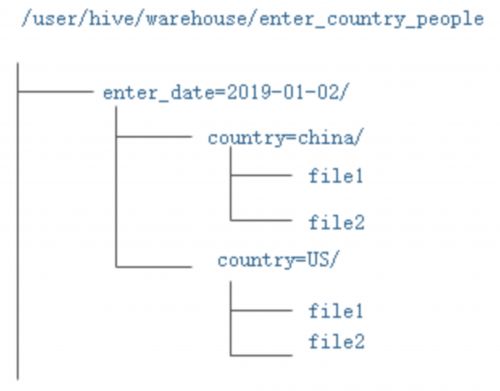
create table enter_country_people(id int,name string,cardNum string)
partitioned by (enter_date string,country string);
注意,这里的分区字段不能包含在表定义字段中,因为在向表中load数据的时候,需要手动指定该字段的值.
数据加载(指定分区):
load data inpath '/hadoop/guozy/data/enter__china_people' into table enter_country_people partition (enter_date='2019-01-02',country='china');
此处自动创建分区目录;
创建完后目录结构:
其他创建分区目录的方法:
1.alter table enter_country_people add if not exists partition (enter_date='2019-01-03',country='US');
2.在相应的表目录下创建分区目录后,执行 msck repair table table_name;
1.5.1.2. 动态分区
建表相同,主要是加载数据方式不同,动态分区是将大杂烩数据自动加载到不同分区目录。
1.开启非严格模式
2.需要从另一张hive表查询
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table enter_country_people(user string,age int) partition(enter_date,country) select user,age,enter_date,country from enter_country_people_bak;
1.5.2. 分桶表
如果两个表根据相同的字段进行分桶,则在对这两个表进行关联的时候可以使用map-side关联高效实现。
create table user_bucket(id int comment 'ID',name string comment '姓名',age int comment '年龄') comment '测试分桶' clustered by (id) sorted by (id) into 4 buckets row format delimited fields terminated by '\t';
指定根据id字段进行分桶,并且分为4个桶,并且每个桶内按照id字段升序排序,如果不加sorted by,则桶内不经过排序的,上述语句中为id,根据id进行hash之后在对分桶数量4进行取余来决定该数据存放在哪个桶中,因此每个桶都是整体数据的随机抽样。
数据载入:
我们需要借助一个中间表,先将数据load到中间表中,然后通过insert的方式来向分桶表中载入数据。
create table tmp_table (id int comment 'ID',name string comment '名字',age int comment '年龄') comment '测试分桶中间表' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
load data inpath '/hadoop/guoxb/data/user.txt' into table tmp_table;
insert into user_bucket select * from tmp_table;
上述的语句中,最终会在hdfs上生成四个文件,而不是四个目录,如果当在次向该分桶表中insert数据后,会又增加4个文件,而不是在原来的文件上进行追加。
1.5.3. 区别
1.hdfs目录结构不同,分区是生成目录,分桶是生成文件
2.分区表在加载数据的时候可以指定加载某一部分数据,有利于查询
3.分桶在map-side join(另一种 reduce-side join)查询时,可以直接从bucket(两表分桶成倍数即可)中提取数据进行关联操作,查询高效。
1.6. Sort By、Order By、Cluster By,Distribute By,group by
order by:会对输入做全局排序,因此***\*只有一个reducer\****(多个reducer无法保证全局有序)。只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
distribute by:按照指定的字段对数据进行划分输出到不同的reduce中(单纯的分散数据)。
sort by:局部排序,sort by只是确保每个reduce上面输出的数据有序,当只有一个reduce时,也变成全局排序。

cluster by:当distribute by 和 sort by 所指定的字段相同时,即可以使用cluster by
group By Key算子的功能固定,只能输出相同key值的序列,reduceByKey适用于分组排序过程中有数据聚合操作(sum)的情形,在其他场景下可能不适用。

受限于reduce数量,设置reduce参数mapred.reduce.tasks 输出文件个数与reduce数相同,文件大小与reduce处理的数据量有关,网络负载过重 数据倾斜,优化参数hive.groupby.skewindata为true,会启动一个优化程序,避免数据倾斜
1.7. SQL
1.7.1. 开窗函数
1.8. 数据倾斜怎么解决
1.key 尽量打乱;提高reduce任务数
2.关联查询时,利用分桶和map-side提高查询效率
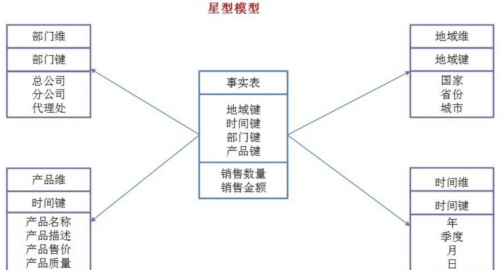
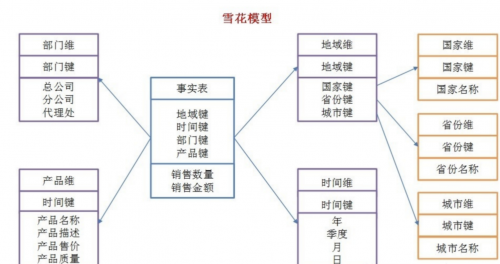
1.9. 星型模型和雪花模型介绍
星型模型:所有的维表直接连接到事实表:
雪花模型:
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,是星型模型的拓展。
更多关于大数据培训的问题,欢迎咨询千锋教育在线名师。千锋教育拥有多年IT培训服务经验,采用全程面授高品质、高体验培养模式,拥有国内一体化教学管理及学员服务,助力更多学员实现高薪梦想。








