Spark 数据倾斜调优10策(一)

何谓数据倾斜?数据倾斜指的是并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
一、数据倾斜概述
1.1 什么是数据倾斜
对Hadoop、Spark、Flink这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
何谓数据倾斜?数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
对于分布式系统而言,理想情况下,随着系统规模(节点数量)的增加,应用整体耗时线性下降。如果一台机器处理一批大量数据需要120分钟,当机器数量增加到三时,理想的耗时为120 / 3 = 40分钟,如下图所示
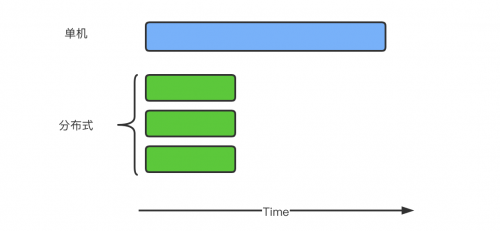
但是,上述情况只是理想情况,实际上将单机任务转换成分布式任务后,会有overhead,使得总的任务量较之单机时有所增加,所以每台机器的执行时间加起来比单台机器时更大。这里暂不考虑这些overhead,假设单机任务转换成分布式任务后,总任务量不变。
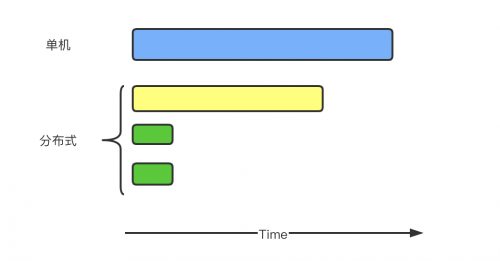
但即使如此,想做到分布式情况下每台机器执行时间是单机时的1 / N,就必须保证每台机器的任务量相等。不幸的是,很多时候,任务的分配是不均匀的,甚至不均匀到大部分任务被分配到个别机器上,其它大部分机器所分配的任务量只占总得的小部分。比如一台机器负责处理80%的任务,另外两台机器各处理10%的任务,如下图所示
1.2 数据倾斜发生时的现象
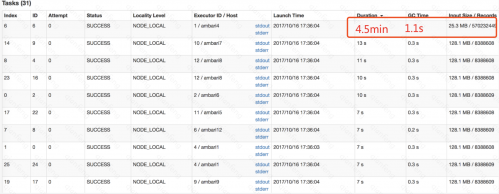
• 绝大多数 task 执行得都非常快,但个别 task 执行极慢。比如,总共有 1000 个 task,997 个 task 都在 1 分钟之内执行完了,但是剩余两三个 task 却要一两个小时。这种情况很常见。
• 原本能够正常执行的 Spark 作业,某天突然报出 OOM(内存溢出)异常,观察异常栈,是我们写 的业务代码造成的。这种情况比较少见。
• Task 类似下图所示
总结:
1. 大部分任务都很快执行完,用时也相差无几,但个别Task执行耗时很长,整个应用程序一直处于99%左右 的状态。
2. 一直运行正常的Spark Application昨晚突然OOM了。
1.3 数据倾斜发生的原理
数据倾斜的原理很简单: 在进行 shuffle 的时候,必须将各个节点上相同的 key 的数据拉取到某个节点 上的一个 task 来进行处理,比如按照 key 进行聚合或 join 等操作。此时如果某个 key 对应的数据量特 别大的话,就会发生数据倾斜。比如大部分 key 对应 10 条数据,但是个别 key 却对应了 100 万条数 据,那么大部分 task 可能就只会分配到 10 条数据,然后 1 秒钟就运行完了;但是个别 task 可能分配 到了 100 万数据,要运行一两个小时。因此,整个 Spark 作业的运行进度是由运行时间最长的那个 task 决定的。
因此出现数据倾斜的时候,Spark 作业看起来会运行得非常缓慢,甚至可能因为某个 task 处理的数据 量过大导致内存溢出。
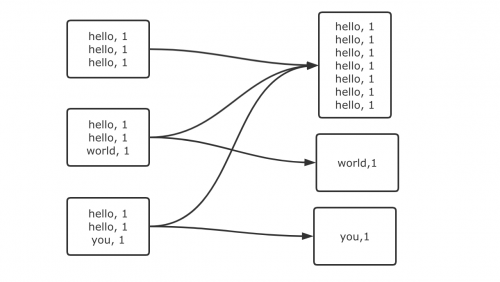
下图就是一个很清晰的例子:hello 这个 key,在三个节点上对应了总共 7 条数据,这些数据都会被拉 取到同一个task中进行处理;而world 和 you 这两个 key 分别才对应 1 条数据,所以另外两个 task 只 要分别处理 1 条数据即可。此时第一个 task 的运行时间可能是另外两个 task 的 7 倍,而整个 stage 的 运行速度也由运行最慢的那个 task 所决定。
总结:
* 数据倾斜发生的本质,就是在执行多阶段的计算的时候,中间的shuffle策略可能导致分发到下 游Task的数据量不均匀,进而导致下游Task执行时长的不一致。不完全均匀是正常的,但是如果相差太大,那么就产生性能问题了。
1.4 数据倾斜的危害
从上图可见,当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发 挥分布式系统的并行计算优势。另外,当发生数据倾斜时,
少量部分任务处理的数据量过大,可能造成 内存不足使得任务失败,并进而引进整个应用失败。如果应用并没有因此失败,但是大量正常任务都早 早完成处于等待状态,资源得不到充分利用。
总结:
1. 整体耗时过大(整个任务的完成由执行时间最长的那个Task决定)
2. 应用程序可能异常退出(某个Task执行时处理的数据量远远大于正常节点,则需要的资源容易出现瓶颈, 当资源不足,则应用程序退出)
3. 资源闲置(处理等待状态的Task资源得不到及时的释放,处于闲置浪费状态)
1.5 数据倾斜是如何造成的
在 Spark 中,同一个 Stage 的不同 Partition 可以并行处理,而具有依赖关系的不同 Stage 之间是串行 处理的。假设某个 Spark Job 分为Stage0 和 Stage1 两个 Stage,且 Stage1 依赖于 Stage0,那 Stage0 完全处理结束之前不会处理 Stage1。而 Stage0 可能包含 N 个Task,这 N 个 Task 可以并行进行。如 果其中 N-1 个 Task 都在 10 秒内完成,而另外一个 Task 却耗时 1 分钟,那该 Stage 的总时间至少为 1 分钟。换句话说,一个 Stage 所耗费的时间,主要由最慢的那个 Task 决定。由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。Stage 的数据来源主要分为如下两类:
1. 数据源本身分布有问题:从数据源直接读取。如读取HDFS,Kafka,有可能出现,大概率不会
2. 自己指定的分区规则:读取上一个 Stage 的 Shuffle 数据
朴素的分布式计算的核心思想:
1. 大问题拆分成小问题:分而治之
2. 既然要分开算,那最后就一定要把分开计算的那么多的小 Task 的结果执行汇总
3. 所以必然分布式计算引擎的设计中,应用程序的执行一定是分阶段
4. 分布计算引擎的而核心:一个复杂的分布式计算应用程序的执行肯定要分成多个阶段,每个阶段分布式并 行运行多个Task
5. DAG引擎:
Spark: stage1 ==> stage2 ===> stage3
mapreduce: 就只有两个阶段:mapper reducer
阶段与阶段之间需要进行 shuffle,只要进行了数据混洗,就存在着数据分发不均匀的情况。如果情况严 重,就是数据倾斜。
分布式计算引擎的设计,免不了有shuffle,既然有shuffle操作,就一定有产生数据倾斜的可能。如果 你是做大数据处理的,就一定会遇到 数据倾斜!







