大数据面试题:经典面试题答疑集合
发布时间:2022-06-29 16:34:48
发布人:syq

1.kafka高吞吐量
答案:
1)消息顺序写到磁盘
2)分区
3)零拷贝:跳过“用户缓冲区”的拷贝,消费者直接通过offset位置,批量拉取消息
4)生产者,通过缓存批量发送消息
2.kafka优缺点
答案:
1)只能支持统一分区内消息有序,无法实现全局消息有序
2)会丢失数据和重复消费数据
3.kafka分区数过多引发的弊端
答案:
1)分区数过多,客户端内存会有小幅度增加;当分区数远大于消费端,线程频繁切换,影响性能;
2)文件句柄开销
3)broker主机down恢复问题,如果分区数过多,单一broker就会承载很多分区,在down过程涉及到的leader重选举和恢复过程中的在均衡时间消耗就比较长。
4.flink的开发中用了哪些算子?
答案:
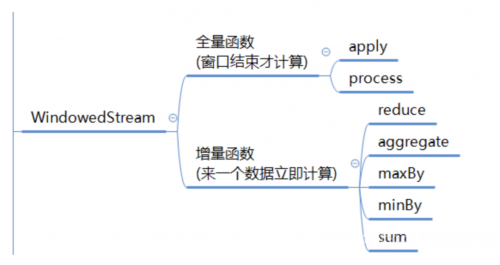

max/min 操作 会根据用户指定的字段取最小值(而字段外的其他值 并不能保证正确) 而maxBy/minBy 指的是自己本身的这条数据。
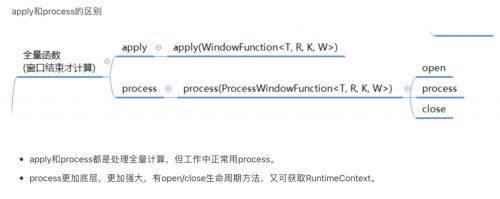

在reduce和aggregate中,都有一个可以把增量函数和全量函数结合使用的方法,就是上面图中标红色五角星的。
对于一个窗口来说,Flink先增量计算,窗口关闭前,将增量计算结果发送给ProcessWindowFunction作为输入再进行处理。
reduce和aggregate区别:aggregate是增强版的reduce,都是增量函数,都有中间结果产生,但是aggregate处理方法更全。

更多关于大数据培训的问题,欢迎咨询千锋教育在线名师。千锋教育拥有多年IT培训服务经验,采用全程面授高品质、高体验培养模式,拥有国内一体化教学管理及学员服务,助力更多学员实现高薪梦想。
下一篇云计算面试题01







