【操作教程】累加器和广播变量在哪些场景使用

累加器和广播变量在哪些场景使用?累加器是分布式的并且共享只写变量。如果在转换运算符中调用了累加器,并且没有后续的动作运算符,则不会执行累加器。如果后面两次调用action操作符,累加器会被执行两次,导致过度加法。

1、广播变量的使用介绍
解决的场景:
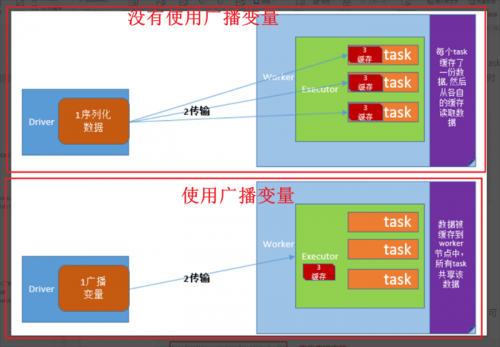
将Driver进程的共享数据发送给所有子节点的Executor进程的每个任务。如果不使用广播变量技术,Driver端默认会将共享数据分发给各个[Task],对网络分发造成很大压力。
如果采用广播变量技术,Driver端的共享数据只会发送给每个[Executor]。 Executor 中的所有任务都重用这个对象。确保共享对象是[可序列化的]。因为跨节点传输的数据必须是可序列化的。
将共享对象广播到Driver端的每个Executor:
val bc = sc.broadcast(共享对象)
在执行器中获得:
bc.值
2、累加器的使用方法
集群中的所有 Executor 对同一个变量执行累积操作。 Spark 目前只支持累加 [add] 操作。内置3个累加器:【LongAccumulator】、【DoubleAccumulator】、【CollectionAccumulator】。
如何使用整数累加器?
在Driver端定义整数累加器并赋初值。
acc=sc.accumulator(0)
Executor端每次累加1
acc+=1
或者 acc.add(1)
3、综合案例


以上代码不仅练习了累加器和广播变量在哪些场景使用,还练习了如何使用函数式编程(Map、Filter),如何创建上下文变量,以及如何使用并行性。这些练习比较全面,希望能帮助你学习更多技能。更多关于IT大数据培训的问题,欢迎咨询千锋教育在线名师,如果想要了解我们的师资、课程、项目实操的话可以点击咨询课程顾问,获取试听资格来试听我们的课程,在线零距离接触千锋教育大咖名师,让你轻松从入门到精通。








