Spark Streaming 反压机制(Back Pressure)

Spark Streaming 反压机制是1.5版本推出的特性,用来解决处理速度比摄入速度慢的情况,简单来讲就是做流量控制。当批处理时间(Batch Processing Time)大于批次间隔(Batch Interval,即 BatchDuration)时,说明处理数据的速度小于数据摄入的速度,持续时间过长或源头数据暴增,容易造成数据在内存中堆积,最终导致Executor OOM。反压就是来解决这个问题的。

spark streaming的消费数据源方式有两种:
若是基于Receiver的数据源,可以通过设置spark.streaming.receiver.maxRate来控制最大输入速率;
若是基于Direct的数据源(如Kafka Direct Stream),则可以通过设置spark.streaming.kafka.maxRatePerPartition来控制最大输入速率。
当然,在事先经过压测,且流量高峰不会超过预期的情况下,设置这些参数一般没什么问题。但最大值,不代表是最优值,最好还能根据每个批次处理情况来动态预估下个批次最优速率。
在Spark 1.5.0以上,就可通过背压机制来实现。开启反压机制,即设置spark.streaming.backpressure.enabled为true,Spark Streaming会自动根据处理能力来调整输入速率,从而在流量高峰时仍能保证最大的吞吐和性能
Spark Streaming的反压机制中,有以下几个重要的组件:
RateController
RateController 组件是 JobScheduler 的监听器,主要监听集群所有作业的提交、运行、完成情况,并从 BatchInfo 实例中获取以下信息,交给速率估算器(RateEstimator)做速率的估算。
当前批次任务处理完成的时间戳 (processingEndTime)
该批次从第一个 job 到最后一个 job 的实际处理时长 (processingDelay)
该批次的调度时延,即从被提交到 JobScheduler 到第一个 job 开始处理的时长(schedulingDelay)
该批次输入数据的总条数(numRecords)
RateEstimator
Spark 2.x 只支持基于 PID 的速率估算器,这里只讨论这种实现。基于 PID 的速率估算器简单地说就是它把收集到的数据(当前批次速率)和一个设定值(上一批次速率)进行比较,然后用它们之间的差计算新的输入值,估算出一个合适的用于下一批次的流量阈值。这里估算出来的值就是流量的阈值,用于更新每秒能够处理的最大记录数
RateLimiter
以上这两个组件都是在Driver端用于更新最大速度的,而RateLimiter是用于接收到Driver的更新通知之后更新Executor的最大处理速率的组件。RateLimiter是一个抽象类,它并不是Spark本身实现的,而是借助了第三方Google的GuavaRateLimiter来产生的。它实质上是一个限流器,也可以叫做令牌,如果Executor中task每秒计算的速度大于该值则阻塞,如果小于该值则通过,将流数据加入缓存中进行计算。
* 反压机制真正起作用时需要至少处理一个批:由于反压机制需要根据当前批的速率,预估新批的速率,所以反压机制真正起作用前,应至少保证处理一个批。
* 如何保证反压机制真正起作用前应用不会崩溃:要保证反压机制真正起作用前应用不会崩溃,需要控制每个批次最大摄入速率。若为Direct Stream,如Kafka Direct Stream,则可以通过spark.streaming.kafka.maxRatePerPartition参数来控制。此参数代表了 每秒每个分区最大摄入的数据条数。假设BatchDuration为10秒,spark.streaming.kafka.maxRatePerPartition为12条,kafka topic 分区数为3个,则一个批(Batch)最大读取的数据条数为360条(3*12*10=360)。同时,需要注意,该参数也代表了整个应用生命周期中的最大速率,即使是背压调整的最大值也不会超过该参数。
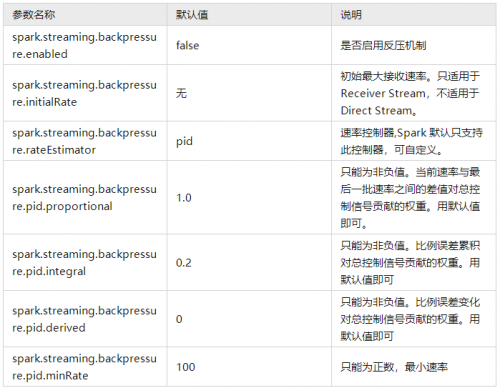
反压相关的参数
更多关于大数据培训的问题,欢迎咨询千锋教育在线名师,如果想要了解我们的师资、课程、项目实操的话可以点击咨询课程顾问,获取试听资格来试听我们的课程,在线零距离接触千锋教育大咖名师,让你轻松从入门到精通。
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!








