padndas提供了丰富的统计、合并、分组、缺失值等操作函数

排序
排序:即对里面的数据按照大小,或者按照某种规则排序。
对DataFrame数据进行排序与Series相似,Dataframe也有按sort_values()与 sort_index()分别按照值、索引进行排序。
参数by=“columns_name”指定排序值参考列,默认ascending=True按升序排序,指定inplace=True,将同时修改原数据。可传入axis=1,按行标签排序,不过用到的时候不多。
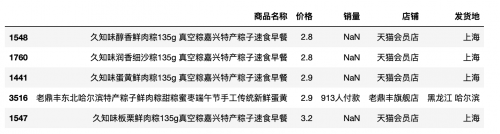
以近期粽子销售数据为例介绍sort_values()的使用,数据结构如下:

比如我们按照价格进行排序,注意默认是升序:
import pandas as pd
import numpy as np
# 按照发货地分组
df = pd.read_csv('zongzi.csv')
df1 = df.sort_values(by='价格')
df1.head()
结果:
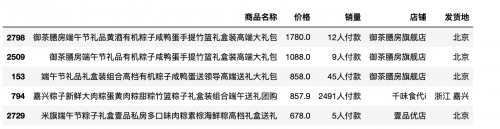
如果按照降序排列,则需要添加参数ascending=False
df1 = df.sort_values(by='价格',ascending=False)df1.head()
结果:
统计函数
padndas提供了丰富的统计、合并、分组、缺失值等操作函数。
比如灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。而如果使用groupby函数则肯定与下面的统计函数息息相关。
常用的统计函数有:
df.count() 非空元素计算
df.min() 最小值
df.max() 最大值
df.idxmin() 最小值的位置,类似于R中的which.min函数
df.idxmax() 最大值的位置,类似于R中的which.max函数
df.quantile(0.1) 10%分位数
df.sum() 求和
df.mean() 均值
df.median() 中位数
df.mode() 众数
df.var() 方差
df.std() 标准差
df.mad() 平均绝对偏差
df.skew() 偏度
df.kurt() 峰度
df.describe() 一次性输出多个描述性统计指标
groupby使用介绍
分组运算"split-apply-combine"(拆分-应⽤-合并)。第⼀个阶段,pandas对象(⽆论是Series、DataFrame还是其他的)中的数据会根据你所提供的⼀个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执⾏的。例如,DataFrame可以在其⾏(axis=0)或列(axis=1)上进⾏分组。然后,将⼀个函数应⽤(apply)到各个分组并产⽣⼀个新值。最后,所有这些函数的执⾏结果会被合并(combine)到最终的结果对象中。
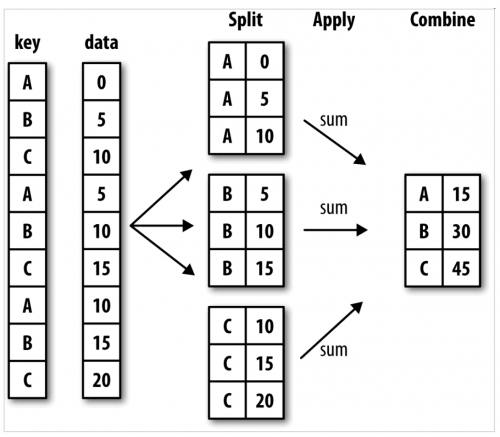
groupby的语法结构如下:
* by 分组的行或者列
* axis=0 行 / 1 列
* 如果有多层索引可以使用level
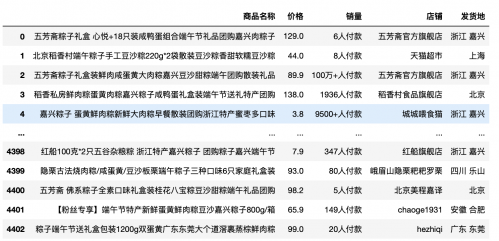
以近期粽子销售数据为例介绍groupby的使用:
数据结构如下
groupby对象的属性和内容获取
import pandas as pd
import numpy as np
# 按照发货地分组
df = pd.read_csv('zongzi.csv')
grouped = df.groupby('发货地')
print(grouped)
打印结果:
<pandas.core.groupby.generic.dataframegroupby 0x11a97a950="" at="" object="">
查看grouped的组成groups
grouped.groups
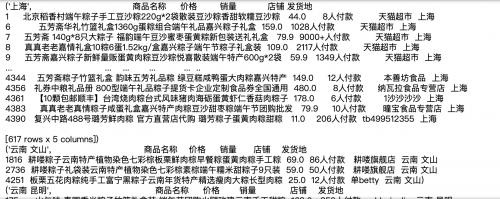
当然大家也可以对grouped进行遍历查看结果:
for group in grouped: print(group)
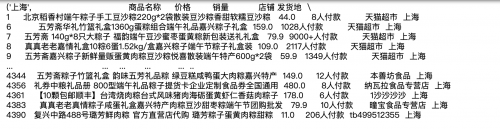
这么多分组,我们可以选择一个分组进行查看:
grouped.get_group('上海')
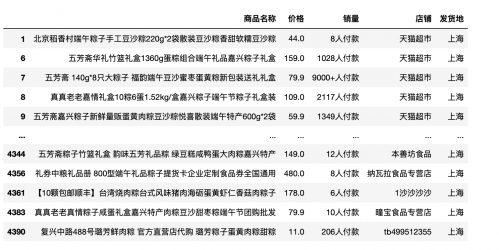
按照某一列分组并进行统计
# 结合统计函数count(),进行发货地的个数统计
import pandas as pd
import numpy as np
# 按照产地分组并统计个数
df = pd.read_csv('zongzi.csv')
grouped = df.groupby('发货地')
grouped['发货地'].count().sort_values(ascending=False) # 统计各个发货地的个数并降序排列
结果:

当然也可以获取各个店铺商品的数量(注意如果是各个店铺则是按照店铺分组,然后再对商品名称进行个数统计)
df['商品名称'].groupby(df['店铺']).count().sort_values(ascending=False)
结果:
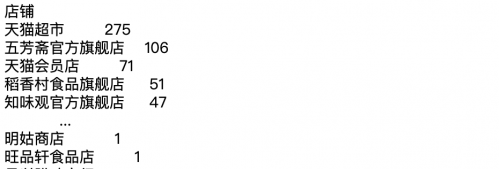
各个店铺的销量总和,销量列是字符串列
df.info()

所以在进行求和之前我们要进行转换,只提取销量的数字变成整型类型的
import pandas as pd
import numpy as np
import re
df = pd.read_csv('zongzi.csv')
# 清洗缺失值的数据,进行填充
df['销量'].fillna('0人付款', inplace=True)
def convert_sale(row):
if '+' in row['销量']:
row['销量'] = row['销量'].replace('+', '')
print(row)
if '万' in row['销量']:
return float(re.search(r'(.+)万人付款', row['销量']).group(1)) * 10000
else:
return int(re.search(r'(.+)人付款', row['销量']).group(1))
df['销量1'] = df.apply(convert_sale, axis=1)
然后计算总和:
df['销量1'].groupby(df['店铺']).sum().sort_values(ascending=False)
按照多列分组,比如每个发货地的各个店铺的销量总和
df.groupby(['发货地','店铺'])['销量1'].sum().sort_values(ascending=False)
获取分组后的某一部分数据可以使用如下格式:
grouped = df.groupby(by=['O', 'N'])
grouped.count()['M']
或
grouped['M'].count()
所以运行后的结果:

当然还有一些复杂的使用,下篇文章给大家详细介绍。
更多关于“Python培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。








