大数据面试题:kafka
发布时间:2022-06-21 17:41:00
发布人:syq

1. AR,ISR,OSR
AR(所有副本)=ISR(在一定程度上与leader副本保持同步,包括leader副本)+OSR(与leader滞后太多的副本,不包括leader副本)
在正常情况下,AR应该是和ISR一样的,但是当某个Follower副本落后太多或者某个Follower副本节点挂掉了,那么它会被移出ISR放入OSR中,kafka的选举也比较简单,就是把ISR中的第一个副本选举成新的Leader节点。比如现在AR=[1,2,3],1挂掉了,那么ISR=[2,3],这时会选举2为新的Leader。
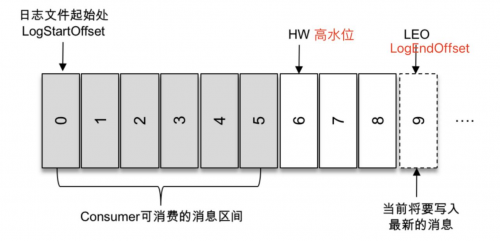
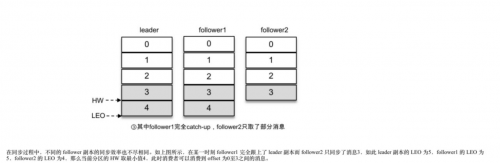
2. ISR 与 HW 和 LEO 关系
LEO的最小值是该分区的HW,当所有副本都复制成功后,LEO与HW相等
3. 重要参数


更多关于“大数据培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。





