运营小白必知:Web Scraper爬虫工具使用教程

作为一名合格的操作员,往往需要掌握数据分析技能。例如,加入去新公司负责编辑新媒体内容,需要盘点公司现有的内容资产,以避免重复内容制作。这时候就需要把网页上的数据刮下来,放在一起,一目了然。从网页爬取数据最好的方法当然是爬虫工具啦~本文将介绍Web Scraper爬虫工具使用教程,帮助小白快速上手爬虫工具!

第 1 步:下载网页抓取工具
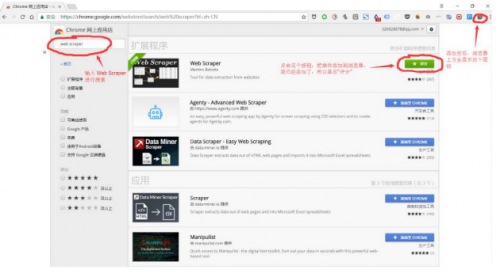
Web Scraper 是 Chrome 浏览器上的一个插件。您需要进入 Chrome App Store 并下载 Web Scraper 插件。
第 2 步:打开 Web Scraper
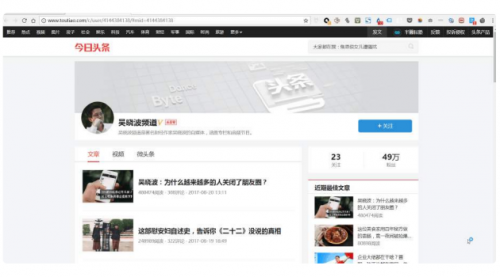
首先打开一个您要抓取数据的网页。比如今天我要抓取今日头条账号“吴晓波频道”的文章标题、时间、评论数,那我就先打开,再操作。然后使用快捷键 Ctrl + Shift + I / F12 打开 Web Scraper。
第 3 步:创建新站点地图
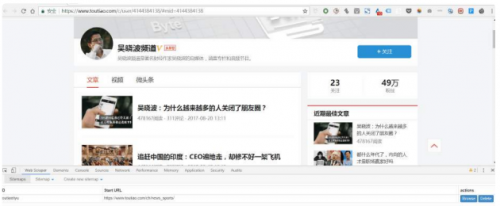
点击Create New Sitemap,有两个选项,import sitemap是引导进入一个现成的sitemap,操作小白一般不是现成的,所以一般不选这个,选create sitemap就好了。然后做这两个操作:
Sitemap Name:表示你的Sitemap适用于哪个网页,所以你可以根据网页来命名,但是需要用英文字母,比如我抓到今天头条的数据,那我就命名它与头条; Sitemap URL:将网页链接复制到Star URL栏,如图,我把“吴晓波频道”的首页链接复制到了这个栏。
第 4 步:设置站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择选中的抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
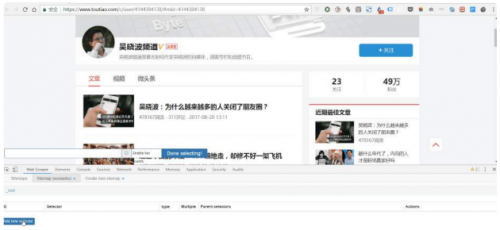
再举个例子,如果要获取福建人的姓名、性别、年龄这三个元素,那么你必须这样做:首先定位福建省,然后定位福建省的人名。 、性别、年龄。这里,一级Selector表示要圈出中国大国中的福建省,二级Selector表示要圈出福建省人口中的姓名、性别、年龄三个要素对于文章,一级Selector表示需要圈出本文的元素。这个元素可能包括标题、作者、发表时间、评论数等,然后我们会在二级Selector中挑选出来。我们想要的元素,例如标题、作者、阅读次数。
(1)点击添加新选择器创建一级选择器,步骤如下:
a.输入id:id代表你抓取的整个范围,比如这里有一篇文章,我们可以命名为126 wuxiaobo-articles;
b. Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要使用Element整体选择(如果这个网络页面需要滑动加载更多,然后选择Element Scroll Down);
c. Check Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选时,爬虫插件会帮助我们识别多篇相似文章;
d. 保留设置:其余未提及的部分保留默认设置。
(2)点击选择范围,按以下步骤操作:
a.选择范围:用鼠标选择要爬取数据的范围,绿色为要选中的区域,鼠标点击后变为红色即为选中;
b.多选:不要只选一个,下面的也不能选,否则只会爬出一行数据;
c.完成选择:记得点击完成选择;
d.保存:点击保存选择器。
(3)设置一级Selector后,点击设置二级Selector,按以下步骤操作:
a.新选择器:点击添加新选择器;
b.输入id:id代表你在抓取哪个字段,所以可以取字段的英文,比如我要选择“作者”,就写“作者”;
c. Select Type:选择Text,因为你要抓取的是文本;
d.不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里是抓取单个元素;保留设置:将其余未提及的部分保留为默认设置。
(4)点击选择,然后点击要爬取的字段,按照以下步骤操作:
a.选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击一篇文章的标题。当字段区域变为红色时,即被选中;
c.完成选择:记得点击完成选择;
d.保存:点击保存选择器。
(5)重复以上操作,引导你选择你要爬的场地。
第 5 步:抓取数据
之所以说Web Scraper是任何新手必备的爬虫工具,是因为你只需要设置好所有的Selector,然后就可以开始爬取数据了。怎么这么简单?那么如何开始爬取数据呢? 只需一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后勤奋的小爬虫就开始工作了。您将获得一个列表,其中包含您想要的所有数据。
以上是小白必知的Web Scraper爬虫工具使用教程。怎么样,Web Scraper 的所有操作你都快开始了吗?相信即使是不懂编程语言的小白也能掌握5分钟爬取数据的爬虫工具!更多关于全媒体培训的问题,欢迎咨询千锋教育在线名师。千锋教育拥有多年IT培训服务经验,采用全程面授高品质、高体验培养模式,拥有国内一体化教学管理及学员服务,助力更多学员实现高薪梦想。








