教你用Python爬虫自制有道翻译词典

Python爬虫能够实现的功能有很多,就看你如何去使用它了,今天小千就来教大家如何去利用Python爬虫自制一个有道翻译词典。
首先打开有道翻译页面,尝试输入hello,就出现翻译了,可以自动翻译。有同学写了爬虫去请求上面的 的链接,宋姐姐要说错啦。因为这个是通过ajax实现的。如何实现的呢?谷歌浏览器F12或者右键选择->检查.

大家点开请求可以看到下图 :
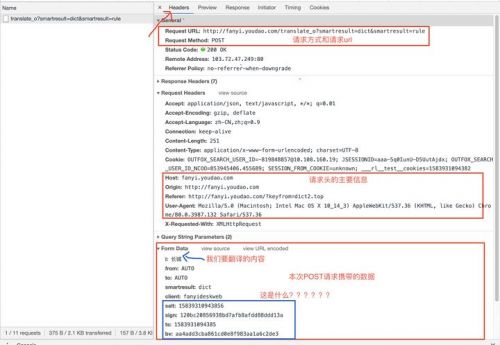
接下来重点来了,难点来了!!!salt,sign,ts,bv表示什么?如果不携带可不可以?
其实这个是js中创建出来的并在每次请求的时候加载到这里的?怎么知道这个值是什么?这时我们就要查看源代码了,右键--->查看源代码:
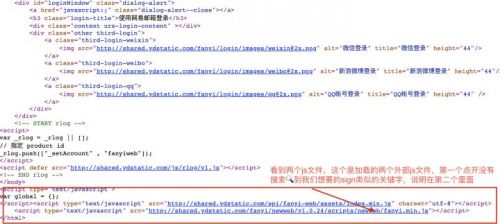
这个文件的js就是我们要找的,点开js文件看看是啥?

哇塞这个是什么鬼?直接吓跑大家。此时考验到家耐心和信心的地方到啦 ,我们有工具可以直接格式化这些的,站长工具点开就可了,切记将所有的代码复制粘贴到里面直接格式化就可以。将格式化好的拷贝到你的pycharm中,然后strl+f查找‘sign’。(切记按照步骤)
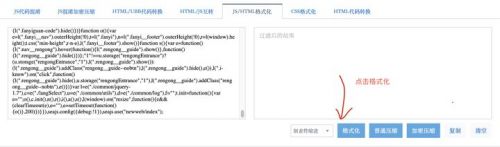
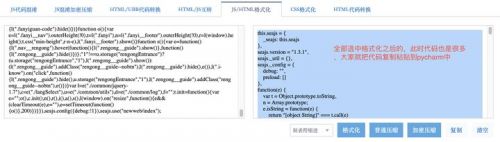
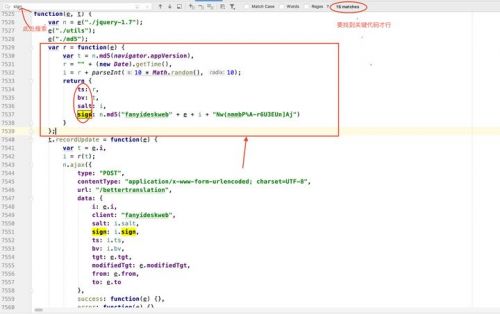
可以分析出:
ts:就是时间戳,而js的时间戳是13位如:1583934479084,python的time.time()是浮点型的如:1583934450.832445 ,要想得到js的时间戳就要是: r= str(int(time.time() * 1000))
bv:n.md5(navigator.appVersion) 表示浏览器版本进行md5加密
salt:r + parseInt(10 * Math.random(), 10); 表示的是时间戳拼接一个0-9的随机数
python实现就是:f = r + str(random.randint(0, 9))
sign:n.md5("fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj")
其中e表示要查询的内容,此时如果我们要查询长城则e=‘长城’
i就是你的salt值,与前面的常量值 “fanyideskweb” 和后面的常量值“Nw(nmmbP%A-r6U3EUn]Aj” 进行拼接后使用md5加密
补充python的md5加密:

此时我们需要的内容全部准备完毕!
通过请求获取的返回结果response是json格式的,此时可以使用bejson.com 进行格式化

所以我们通过json就方便提取数据了,其中‘tgt’就是翻译后的内容。

不说那么多了上代码:

大家将代码运行一下看到:{“errorCode”:50} 的结果没有翻译成功!这是为啥呢?
就是大家在爬取的时候将链接:url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
中的‘_o’务必切记去除掉,这个也是有道反扒的一种机制。(这个可能就是困扰很多同学的地方)
学习Python,可以参考千锋Python培训班推出的Python开发学习路线,结合千锋Python培训机构名师精心录制的全套Python视频教程,可以让你对学习Python需要掌握的知识有个清晰的了解,并快速入门Python开发。千锋Python培训机构视频教程分为三个大块:Python基础视频教程、Python高级视频教程、Python高手晋级视频教程。视频讲解通俗易懂,入门Python开发仅用此套视频足矣。想要获取免费Python学习路线和学习资料可以添加我们的Python技术交流qq群:790693323 加群找群管理领取即可,Python相关技术问题也可以加群解决,等你来哦~~~~








