大数据面试题:MapReduce的join过程及hive的SQL解析过程
发布时间:2022-06-20 17:57:00
发布人:syq

1.MapReduce的join过程

miJoin(半连接)
(1):利用DistributedCache将小表分发到各个节点上,在Map过程的setup()函数里,读取缓存里的文件,只将小表的连接键存储在hashSet中。
(2):在map()函数执行时,对每一条数据进行判断(包含小表数据),如果这条数据的连接键为空或者在hashSet里不存在,那么则认为这条数据无效,这条数据也不参与reduce的过程。
2. hive的SQL解析过程
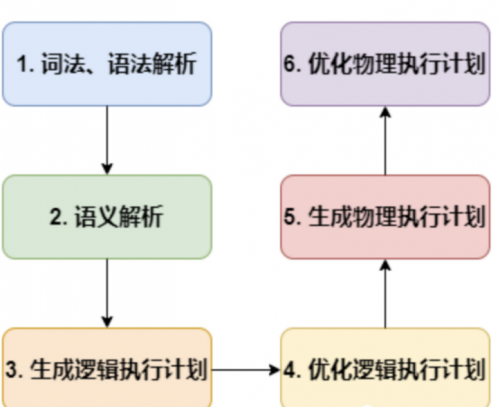
词法、语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
语义解析:遍历 AST Tree(抽象语法树,抽象语法结构的树状),抽象出查询的基本组成单元 QueryBlock;
生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少 MapReduce Job,减少数据传输及 shuffle 数据量。
更多关于“大数据培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。





