大数据面试题:分区和分桶

一、分区
指的就是将数据按照表中的某一个字段进行统一归类,并存储在表中的不同的位置,也就是说,一个分区就是一类,这一类的数据对应到hdfs存储上就是对应一个目录。
1.静态分区
数据已经按某些字段分完区放在一块,建表时直接指定分区即可。
create table entercountrypeople(id int,name string,cardNum string)
partitioned by (enter_date string,country string);
注意,这里的分区字段不能包含在表定义字段中,因为在向表中load数据的时候,需要手动指定该字段的值.
2.数据加载(指定分区):
load data inpath '/hadoop/guozy/data/enter_chinapeople' into table entercountrypeople partition (enter_date='2019-01-02',country='china');
此处自动创建分区目录;
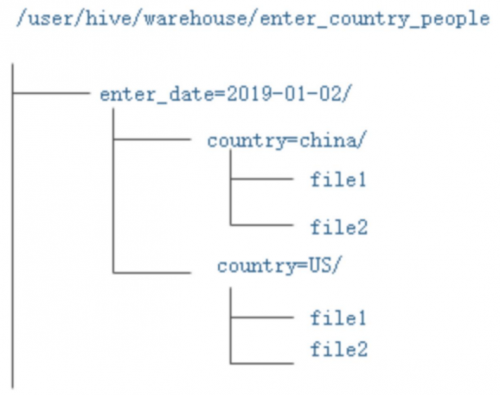
创建完后目录结构:
其他创建分区目录的方法:
1)alter table entercountrypeople add if not exists partition (enter_date='2019-01-03',country='US');
2)在相应的表目录下创建分区目录后,执行 msck repair table table_name;
2.动态分区
建表相同,主要是加载数据方式不同,动态分区是将大杂烩数据自动加载到不同分区目录。
1)开启非严格模式
2)要从另一张hive表查询
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table entercountrypeople(user string,age int) partition(enterdate,country) select user,age,enterdate,country from entercountrypeople_bak;
二、分桶表
如果两个表根据相同的字段进行分桶,则在对这两个表进行关联的时候可以使用map-side关联高效实现
create table user_bucket(id int comment 'ID',name string comment '姓名',age int comment '年龄') comment '测试分桶' clustered by (id) sorted by (id) into 4 buckets row format delimited fields terminated by '\t';
指定根据id字段进行分桶,并且分为4个桶,并且每个桶内按照id字段升序排序,如果不加sorted by,则桶内不经过排序的,上述语句中为id,根据id进行hash之后在对分桶数量4进行取余来决定该数据存放在哪个桶中,因此每个桶都是整体数据的随机抽样。
数据载入:
我们需要借助一个中间表,先将数据load到中间表中,然后通过insert的方式来向分桶表中载入数据。
create table tmp_table (id int comment 'ID',name string comment '名字',age int comment '年龄') comment '测试分桶中间表' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
load data inpath '/hadoop/guoxb/data/user.txt' into table tmp_table;
insert into userbucket select * from tmptable;
上述的语句中,最终会在hdfs上生成四个文件,而不是四个目录,如果当在次向该分桶表中insert数据后,会又增加4个文件,而不是在原来的文件上进行追加。
三、区别
1.hdfs目录结构不同,分区是生成目录,分桶是生成文件
2.分区表在加载数据的时候可以指定加载某一部分数据,有利于查询
3.分桶在map-side join(另一种 reduce-side join)查询时,可以直接从bucket(两表分桶成倍数即可)中提取数据进行关联操作,查询高效。
更多关于“大数据培训”的问题,欢迎咨询千锋教育在线名师。千锋教育多年办学,课程大纲紧跟企业需求,更科学更严谨,每年培养泛IT人才近2万人。不论你是零基础还是想提升,都可以找到适合的班型,千锋教育随时欢迎你来试听。





